高級FPGA系統設計需要研究包括設計方法學、算法和數據結構、編程語言和程序、體系結構與硬線邏輯以及設計與實現工具五個關鍵問題。只有學習掌握好這5個方面的知識,并深刻理解這五個方面的關系,才能做到從總體上把握全系統,設計出滿足要求的高性能數字系統。
FPGA系統設計實質上是一個同步時序系統的設計,理解掌握時序的概念,并能進行正確完整的時序約束,是實現高性能系統的重要保證。本課程按照"從宏觀到微觀,從頂層到底層"的系統設計原則,以"時序分析與設計(Timing Analyzing and Design)"為主線,按照從"高性能內部邏輯設計"到"高速外部接口設計"再到"FPGA嵌入式系統"的順序,深入探討了"FPGA和FPGA數字系統"、"FPGA設計流程與時序收斂"、"Virtex-4和Virtex-5高級資源"、"FPGA高速I/O接口設計"以及FPGA嵌入式系統開發(fā)的高級特性與技術5大主題。課程內容結合了美國相關原版培訓課程和培訓講師的科研教學實踐,理論豐富,實驗合理,具有非常強的系統性和實用性,可以引導學員快速提高FPGA數字系統設計水平,從而能夠更快地創(chuàng)建設計,縮短開發(fā)時間,降低開發(fā)成本。
二、主辦單位:中國高科技產業(yè)化研究會信號處理專家委員會
三、研修時間:2010年06月10-13日(09日報到)
四、地 點:上 海(具體地點及路線圖詳見報到通知)
五、培訓對象
課程適合于使用FPGA器件進行科研和產品開發(fā)的具有中等水平的工程技術人員,也適合于相關專業(yè)領域具有相當水平的教師和研究生。
六、工具平臺
培訓課程使用的所有軟硬件工具由培訓方提供。根據培訓時間和地點的不同,軟硬件版本會有所變化。培訓方可以以優(yōu)惠的價格向學員提供基于Xilinx XC3S500E的高級開發(fā)板一塊,以方便學員在學習結束后繼續(xù)深入研究。本次培訓使用的硬件平臺: XUPV2Pro實驗板。
七、授課大綱
1:FPGA和FPGA數字系統
本節(jié)通過對數字信號處理、計算(Computing)、算法和數據結構、編程語言和程序、體系結構和硬件邏輯以及設計方法學的基本概念和它們之間關系的介紹,使學員從更高的層次上去理解FPGA數字系統的設計問題。通過本節(jié),希望學員能夠理解現代電子系統的三大基本關系(模擬系統與數字系統的關系/軟件與硬件的關系/同步系統與異步系統的關系),理解FPGA的基本結構和技術特點。
2:FPGA設計流程與時序收斂
FPGA系統設計實質上是一個同步時序系統的設計,深入理解掌握時序的概念,并能使用時序約束工具對設計進行正確的、完整的約束,是實現高性能系統的重要保證。本節(jié)是對FPGA結構資源、設計流程和設計工具的歸納、總結與升華,使學員透過表面現象看到FPGA設計技術的實質,從而為掌握FPGA高級設計技術打下基礎。
主要內容如下:深入理解FPGA設計和驗證流程;掌握綜合(Synthesize)的不同屬性對性能改善的影響;通過使用高級實現(Implement)屬性增加設計性能;掌握全局時序約束,進一步學習特定路徑時序約束,并使用約束編輯器正確設置系統約束;運用靜態(tài)時序分析工具(Timing Analyzer)和時序收斂流程解決時序問題;深入理解基于FPGA的軟硬件協同系統設計環(huán)境(ISE、EDK、SysGen)。
3:Virtex-4和Virtex-5高級資源
學習掌握最新的FPGA設計分析方法和最流行的FPGA設計工具對實現高性能的FPGA數字系統意義重大。本節(jié)和上一節(jié)重點關注FPGA設計領域的新技術。
Xilinx Virtex-4和Virtex-5 FPGA芯片是目前最先進的可編程邏輯器件。本節(jié)介紹Virtex-4和Virtex-5 FPGA提供的新資源和新設計方法,特別是時鐘系統的設計方法和設計技巧。Virtex-4和Virtex-5高性能的源同步資源和技術為解決芯片間高速通信提供了有力保證。本節(jié)重點學習基于Virtex-4和Virtex-5的 時鐘設計和源同步技術,為高速IO接口設計分析打下基礎。
4:FPGA高速I/O接口設計
FPGA片內工作頻率可以達到500MHz,并且具有強大的并行處理能力,而芯片間接口速度已經成為高性能系統的瓶頸。高速系統主要有三種時鐘結構,即全局時鐘系統、源同步時鐘系統和自同步時鐘系統。本節(jié)重點學習源同步時鐘技術的原理和應用,并有大量實例分析。學員將從理論和實踐兩個方面深入理解源同步技術在高速接口技術中的應用,學習使用靜態(tài)時序分析工具分析高速接口的時序問題,學習使用源同步技術和源同步資源解決高速接口的時序問題。
主要內容如下:學習源同步高速I/O接口技術;使用時序分析器查找接口時序失敗原因,并修改設計以滿足時序要求;分析學習高速多通道串行ADC與FPGA接口設計和高性能DSP芯片與FPGA接口設計。
5:FPGA嵌入式系統高級特性與技術理論授課
隨著FPGA技術的發(fā)展,在FPGA上實現可編程片上系統(PSOC)在技術上已成為可能。基于FPGA的PSOC系統開發(fā)已成為目前FPGA應用的一個熱點。但是基于FPGA的嵌入式系統開發(fā)對使用者的知識要求比較高,流程復雜,相關資料不多,這些都成為目前開發(fā)FPGA嵌入式系統的瓶頸問題。
本部分內容以FPGA嵌入式系統開發(fā)初級班所授的技能為基礎,要求學員具備基本的嵌入式系統開發(fā)以及C語言知識,主要圍繞在嵌入式系統的高級操作和工程應用展開講授,具體包括:Picoblaze、MicroBlaze和PowerPC這兩大類,其中Picoblaze為一個8位的MCU內核,應用方式非常靈活;MicroBlaze和PowerPC為更高級的32位處理內核,前者為軟核,后者為硬核,適合完成復雜的PSOC系統實現。
PicoBlaze 8位微處理器是Xilinx公司為Virtex系列FPGA、Spartan系列FPGA和CoolRunner-II系列CPLD器件設計嵌入式專用IP Core。它解決了常量編碼可編程狀態(tài)機(KCPSM)的問題。這一模塊只占用SpartanIIE的76個小區(qū)(slice),且還包括一個用于存儲指令的由Block RAM組成的ROM,最多可存儲256條指令。在實際工程中頗具"四兩撥千斤"之功效
對于MicroBlaze和PowerPC系統,則更注重存儲器技術、系統加速策略、用戶自定義外設、軟件開發(fā)、啟動加載程序(Boot loader)設計、操作系統、軟硬件協同開發(fā)等核心問題。同時,在實際中,配合FPGA的并行特征,則可以將MicroBlaze和PowerPC看成"大腦",而FPGA的邏輯資源則等效于"心臟、四肢以及五官"等核心組件,只有彼此有機結合才能形成高效的系統。因此在學習基于FPGA的嵌入式系統開發(fā)中,不能簡單認為嵌入式就是全部。這和典型的MCU、ARM以及DSP嵌入式系統有著本質區(qū)別,但就于MicroBlaze和PowerPC內核來講,其和傳統的嵌入式系統實相通的。
因此,本課程基于FPGA平臺將學員帶入一個更為廣闊的視角,同時對理解其他類型的嵌入式應用系統架構會有也有更深的理解。
]]>
2.4 交織邏輯網絡
交織邏輯網絡是基于自對偶函數的自校驗邏輯網絡。一個二進制變量是交替的,記作![]() 若x在兩個連續(xù)的時間間隔內所取的值互補。
若x在兩個連續(xù)的時間間隔內所取的值互補。
對任意一個開關函數![]() ,若假設
,若假設![]() 是交替二進制變量,且它們是同步交替的,則g的輸入矢量可表示為
是交替二進制變量,且它們是同步交替的,則g的輸入矢量可表示為![]() ,其輸出可表示為
,其輸出可表示為![]() ,要使輸出變量也是交替的,必須滿足
,要使輸出變量也是交替的,必須滿足![]() ,顯然,g必須是自對偶函數。利用交織邏輯網絡的這個特點,可以檢測出系統的一部分故障。
,顯然,g必須是自對偶函數。利用交織邏輯網絡的這個特點,可以檢測出系統的一部分故障。
3 自校驗網絡實現方法
對于一些比較簡單的應用場合,利用數字邏輯方法進行設計,使用SSI及MSI集成電路即可方便地構成自校驗網絡。但實際容錯系統非常復雜,涉及大量邏輯設計,若仍采用傳統的數字邏輯設計方法,不僅工作量大、容易出差錯,而且修改和功能仿真都不方便。使用電子設計硬件描述語言VHDL(或Verilog HDL對電路功能進行描述,用FPGA或CPLD器件實現自校驗網絡是比較現實的,對于大批量生產,可將VHDL描述的電路送半導體器件廠進行批量生產,VHDL硬件描述語言實現自校驗網絡的步驟如下:
①建立自校驗網絡的功能模型。對系統的輸入/輸出、狀態(tài)轉換、信號傳遞等進行詳細的說明。
②用VHDL語言或Verilog HDL語言對電路功能進行描述。對復雜系統可采用撟隕隙聰的設計方法,將系統分解成不同層次的、功能較簡單的模塊,利用VHDL語言對系統功能進行分層描述,減少系統描述造成的錯誤。
③對不同層次的模塊進行功能仿真,以檢驗各模塊設計的正確性,最后對整個系統進行功能仿真,及早排除系統設計中的錯誤。
④用VHDL或Verilog HDL綜合編譯器對設計好的系統進行編譯,經過邏輯化簡及綜合布線,生成可對FPG A或CPLD編程的數據文件。
⑤將數據文件通過編程器寫入FPGA或CPLD,進行實際測試,若測試數據滿足設計要求,則開發(fā)工作完成;否則,轉①重新進行檢查和設計。
采用自校驗技術后,可有效地提高容錯系統的可靠性,隨著集成電路技術的飛速發(fā)展,可將一些自校驗功能模塊進行封裝,作為標準單元使用,在模塊級上提高容錯系統的可靠性。采用高級語言和FPGA或CPLD開發(fā)容錯系統具有重要的現實意義,可有效縮短開發(fā)周期,降低開發(fā)成本,提高系統可靠性,應在工程設計中加以推廣應
設組合邏輯網絡正確輸入矢量為![]() ,則矢量空間
,則矢量空間![]() 稱作錯誤輸入空間,記作
稱作錯誤輸入空間,記作![]() ;空間
;空間![]() 被稱作非法及錯誤輸入空間,記作
被稱作非法及錯誤輸入空間,記作![]() 。由正確輸入空間
。由正確輸入空間![]() 經電路G可在S(F)中產生一個子空間,這個子空間稱為正確輸出空間,記為
經電路G可在S(F)中產生一個子空間,這個子空間稱為正確輸出空間,記為![]() 。同樣,對于合法輸入
。同樣,對于合法輸入![]() ,由組合邏輯網絡可映射為合法輸出空間
,由組合邏輯網絡可映射為合法輸出空間![]() 它也是輸出矢量空間S(F)的子集。同樣,空間
它也是輸出矢量空間S(F)的子集。同樣,空間![]() 被稱作錯誤輸出空間,記作
被稱作錯誤輸出空間,記作![]() ;空間
;空間![]() 被稱為非法及錯誤輸出空間,表示為
被稱為非法及錯誤輸出空間,表示為![]() 。上述輸出之間有如下關系:
。上述輸出之間有如下關系:
![]()
由上面集合之間的關系我們可以看出,對于無故障組合網絡的正確輸入,其輸出應落入正確輸出空間![]() 中。通過對網絡的輸出可部分判定系統工作是否正常(無法判斷某些故障)。當網絡發(fā)生故障時,可分成以下幾種情況:①非法及錯誤輸入被映射成
中。通過對網絡的輸出可部分判定系統工作是否正常(無法判斷某些故障)。當網絡發(fā)生故障時,可分成以下幾種情況:①非法及錯誤輸入被映射成![]() ;②輸入
;②輸入![]() 被映射成為
被映射成為![]() ;③
;③![]() 映入
映入![]() 但已不是正確的映射關系,也就是說輸入輸出關系發(fā)生了變化。對于一個高可靠容錯系統來說,必須能夠以比較高的故障覆蓋率來檢測出以上三類差錯(最好在一拍內檢出),使系統及時采取措施,隔離故障,將其影響減小到最低限度。在三類錯誤中,第①類和第②類與第③類相比要好檢測一些,高效檢測第③類錯誤是提高系統故障覆蓋率的關鍵,只有設計出對以上三類錯誤檢出率均較高的檢錯系統,才能保證系統有較高的可靠性。
但已不是正確的映射關系,也就是說輸入輸出關系發(fā)生了變化。對于一個高可靠容錯系統來說,必須能夠以比較高的故障覆蓋率來檢測出以上三類差錯(最好在一拍內檢出),使系統及時采取措施,隔離故障,將其影響減小到最低限度。在三類錯誤中,第①類和第②類與第③類相比要好檢測一些,高效檢測第③類錯誤是提高系統故障覆蓋率的關鍵,只有設計出對以上三類錯誤檢出率均較高的檢錯系統,才能保證系統有較高的可靠性。
2 自校驗網絡的結構
自校驗網絡具有在無任何外加激勵的情況下能自動檢測其內部是否存在故障,這些故障或是永久性的或是暫時性的。設計自校驗網絡的主要技術有檢錯編碼技術,基于自對偶函數的交替邏輯技術(交織邏輯技術),基于對偶函數的互補邏輯技術,還有基于多值邏輯的實現方法,下面我們主要討論一些實用的實現方法。
2.1 雙軌碼校驗器
雙軌碼校驗器的原理圖如圖3所示。
輸入矢量為![]() ,其中
,其中![]() ,(i=1,2),輸出矢量為
,(i=1,2),輸出矢量為![]() 且滿足:
且滿足:

![]() 若
若![]() 且校驗器無故障。
且校驗器無故障。
利用雙軌碼校驗器的上述特點,設計一對偶組合邏輯網絡,使其輸出向量![]() 和
和![]() 恰好反相,將
恰好反相,將![]() 和
和![]() 加到雙軌碼校驗器輸入端,根據
加到雙軌碼校驗器輸入端,根據![]() 就可以判定系統是否發(fā)生故障。
就可以判定系統是否發(fā)生故障。
2.2 可分碼校驗器
可分碼校驗器的結構如圖4所示。校驗器的輸入矢量為![]() ),矢量
),矢量![]() 和
和![]() 分別對應可分碼的信息分量和校驗分量。其中,信息分量寬度為
分別對應可分碼的信息分量和校驗分量。其中,信息分量寬度為![]() 是校驗分量的寬度,且1+K=n, n=‖Y‖。校驗位生成電路根據信息位
是校驗分量的寬度,且1+K=n, n=‖Y‖。校驗位生成電路根據信息位![]() 重新生成校驗位W,由雙軌碼校驗器比較W與
重新生成校驗位W,由雙軌碼校驗器比較W與![]() 的一致性,在無故障的情況下,校驗器的輸出
的一致性,在無故障的情況下,校驗器的輸出![]() 指示輸入矢量的有效性。下面的定理給出了圖4完全自校驗可分碼校驗器的構造條件。
指示輸入矢量的有效性。下面的定理給出了圖4完全自校驗可分碼校驗器的構造條件。
在嵌入式市場里有著大量的低級硬件和軟件工具,同時隨著嵌入式設計和硬件技術(多核處理器、FPGA等等)不斷提高的復雜性,要使用現有工具進行快速原型設計是困難的。
為了節(jié)省在軟件原型開發(fā)中花費的時間和金錢,應當選擇能夠抽象大部分底層工作的工具。使用LabVIEW編程工具進行圖形化系統設計為用戶提供了強大而直觀的開發(fā)環(huán)境,使用戶能夠直接開始進行原型開發(fā)。LabVIEW具有圖形化特性,帶有數千個內建函數塊,可以用于信號處理、高級控制、通信、數據采集、記錄等任務中。此外,LabVIEW能夠在大量復雜的硬件目標上運行,從多核與實時處理器直至FPGA。因為用戶可以使用LabVIEW對FPGA進行編程,可以方便地在原型系統中使用這個技術,而無需浪費大量的開發(fā)時間。
使用狀態(tài)圖從紙上的設計進行過渡
大多數設計或想法是從紙上開始的。無論是寫在餐巾紙上還是更正式的書面計劃,從紙面平穩(wěn)過渡到軟件幫助您更快開始您的設計。工程師在設計嵌入式系統軟件體系結構中,已經使用狀態(tài)圖多年了。在20世紀90年代,狀態(tài)圖被認為是統一建模語言(UML)規(guī)范的行為框圖,廣泛用于對嵌入式系統進行建模。
使用LabVIEW狀態(tài)圖模塊,用戶可以使用狀態(tài)圖框圖設計軟件組件,使用數據流圖形化編程定義狀態(tài)行為和過渡邏輯。圖1展示了用戶如何從紙上的狀態(tài)圖過渡到LabVIEW狀態(tài)圖。
圖1 從紙上的狀態(tài)圖過渡到LabVIEW狀態(tài)圖模塊
快速連接到I/O以及嵌入式傳感器
對于大多數實時嵌入式應用而言,連接到實際的I/O是必須的。因此,在創(chuàng)建原型系統時,使用工具快速地連接到傳感器和致動器是十分重要的。NI提供了豐富的板卡級封裝硬件,其中包括用戶與任何傳感器進行交互的模擬和數字I/O。舉例而言,NI C系列模塊的模塊化特性和靈活性使它們成為原型開發(fā)I/O的理想選擇。
圖2 用于將原型系統連接到傳感器的C系列I/O模塊
用戶可以在基于USB的系統中使用C系列模塊,用于連接NI CompactDAQ、無線設備,甚至例如NI CompactRIO和板卡級NI單板RIO等嵌入式系統。NI和第三方廠商提供了超過80個C系列模塊,用于將用戶的原型系統與模擬、數字、運動、通信以及嵌入式傳感器與原型系統進行交互。此外,用戶可以使用LabVIEW工具對所有這些平臺進行編程,它提供了與所有這些I/O模塊進行交互的驅動程序和庫。
使用開發(fā)式軟件實現您的IP
在大多數情況下,嵌入式設計最重要的部分是嵌入在設計中的控制算法或處理算法,也稱為知識產權。在大多數情況下,用戶可能已經擁有以特定形式開發(fā)的IP(例如ANSI C、文本數學、VHDL或其他)。將IP轉換為功能原型系統將會是耗費時間的過程。選擇一個開放環(huán)境,可以將用戶的IP與原型系統的其他部分整合在一起,這樣可以將工作變得十分簡單。LabVIEW提供了高級開放式環(huán)境,用戶可以用來集成任何現存的C、文本數學以及VHDL IP。
將機械仿真與軟件設計進行整合
“數字原型設計”的概念是將機械設計與軟件設計進行連接的流程的新術語。將控制設計軟件與機械仿真整合在一起幫助您快速開發(fā)原型系統仿真。使用數字原型設計,用戶可以創(chuàng)建虛擬原型系統,而無需構建機械系統。
NI與SolidWorks進行合作,為用戶提供了將機械仿真與控制設計軟件進行整合的功能。這個新功能被加入LabVIEW 2009的NI SoftMotion模塊中,用戶可以在LabVIEW中構建控制設計算法,將控制功能與SolidWorks機械模型整合在一起,使用真實的機械模型對控制算法進行測試,而無需構建機械系統。
使用包含中間件的運行準備好硬件
在嵌入式設計中的最大挑戰(zhàn)之一是創(chuàng)建、調試以及驗證驅動程序級軟件棧,將嵌入式系統的所有硬件組件整合在一起。過去,整合過程需要用戶完成,這將嵌入式原型設計流程變得復雜而且耗時。
NI中間件軟件驅動程序超出了傳統單板計算機和其他嵌入式系統提供的用于提高生產力、性能以及上市時間的基本驅動程序的范疇。驅動程序軟件和其他配置服務軟件包含在每個支持可重復配置I/O(RIO)設備中。內建的中間件軟件驅動程序工具包含以下功能:
? 內建函數,用于與模擬、數字、運動、通信I/O以及FPGA進行交互
? 傳送函數,用于在FPGA與處理器之間進行數據通信
? 用于將FPGA/處理器與內存之間進行交互的方法
? 用于將處理器與外部設備(RS232串行接口、以太網)進行交互的函數
? 高性能的多線程驅動程序
不要忽視HMI
有時候,演示想法最簡單也是最好的方法是通過HMI,即用戶界面。如果用戶可以找到用于快速構建用戶界面的軟件工具,用戶可以與潛在的客戶或投資者一起,在概念設計流程的早期對功能進行測試。
圖3 LabVIEW圖形化編程包含內建用戶界面
LabVIEW圖形化開發(fā)工具為快速建立用戶界面提供了多種選項。首先,每個LabVIEW程序(即VI)包含了應用程序的圖形化代碼和程序的用戶界面。因此,與其他編程語言不同,用戶不需要編寫大量附加的程序構建用戶界面,使用LabVIEW,用戶可以免費得到用戶界面。在LabVIEW中,提供了數百個內建用戶界面項目,從圖表到撥盤直至三維圖片控件,幫助用戶為原型系統快速構建HMI。
測量原型系統
在設計流程的早期完成原型設計的另一個優(yōu)點是它為用戶提供了盡可能完善設計的機會。越早完成原型系統的開發(fā),也就可以越早地開始測試硬件與軟件設計,從而可以建立更加可靠的系統。在許多情況下,用戶可能需要等到完成產品開發(fā)才會開始考慮測試。通過對原型系統進行測試,用戶不僅能夠建立更可靠的產品,而且還可以更早地開始設計生產測試系統。
圖4 來自NI的測試產品用于測試原型系統
在構建原型系統時,考慮能夠使原型系統設計變得更加簡單的工具。用戶可以在原型系統的設計與測試中,使用圖形化系統設計工具。LabVIEW和模塊化測試硬件(基于PC或PXI/CompactPCI技術)能夠用于原型系統中,幫助用戶更早地對設計進行測試。
快速從想法進入現實
原型開發(fā)是嵌入式設計流程的重要部分。向投資者、客戶或管理層展示想法功能的能力是為想法得到預算的最佳方法之一。NI圖形化系統設計工具可以在無需大量開發(fā)時間和大型設計團隊的情況下,快速地完成具備功能的原型系統。在對下一個設計進行原型開發(fā)時,請考慮使用LabVIEW以及NI原型開發(fā)硬件,使原型開發(fā)變得更為快捷。
]]>
目前,為了能夠使用這些最新技術,工程師們往往不得不使用非專為并行編程設計的軟件工具。而最新版的LabVIEW則為他們提供了獨立的平臺,通過采用多核處理器技術提高測試及控制系統的吞吐量,在基于FPGA的高級控制及嵌入式原型應用中縮短開發(fā)時間,更便捷地創(chuàng)建分布式測量系統,采集遠程數據。
“從機器人技術到混合動力汽車設計,為了滿足前沿應用中的性能及效率需求,用戶必須及時將諸如多核處理器、FPGA及無線通信等最新技術融入自己的應用,” NI公司總裁、CEO兼創(chuàng)始人之一James Truchard博士表示,“LabVIEW通過并行編程為上述技術的應用提供了捷徑,同時它也為用戶提供最大的靈活性來針對各種應用領域設計最優(yōu)化的解決方案。”
當標準系統越來越趨于引入多個處理核,測試測量系統實現大幅度性能提升的可能性也就越大。LabVIEW平臺擴展了內嵌的多線程技術,在新版軟件中通過多核優(yōu)化特性提供超級計算性能,幫助工程師處理更大容量的測量數據,滿足高級控制應用的要求,并提高測試系統的吞吐量。
為了提升性能,LabVIEW 8.6包含了超過1,200個重新優(yōu)化的高級分析函數,在多核系統的控制測試應用中提供更快速、更強大的數學及信號處理功能。視覺應用同樣能從多核系統中獲益,NI視覺開發(fā)模塊中創(chuàng)新性的圖像處理函數,能夠自動在多核間分配數據集。在全新的多核特性下,測試工程師通過新版LabVIEW的調制工具包開發(fā)測試無線設備的應用,其效率可提高4倍之多;控制系統工程師通過LabVIEW 8.6 控制設計及仿真模塊實現并行模型仿真,效率可顯著提高5倍之多。此外,使用LabVIEW框圖自動布局功能,工程師們能夠更便捷地識別代碼的并行部分。
借助于LabVIEW直觀的數據流模式,工程師們可以通過使用LabVIEW FPGA模塊及基于FPGA的現成即用的商業(yè)硬件(如NI CompactRIO)來自定義測量及控制系統應用,如半導體驗證及高級機器控制,從而實現更佳的性能。LabVIEW 8.6一如既往地將FPGA技術帶給更多沒有專業(yè)底層硬件描述語言或板級電路設計經驗的工程師們。
LabVIEW 8.6進一步縮短了FPGA的開發(fā)時間,其新特性允許工程師們直接對CompactRIO可編程自動控制器 (PAC) 進行編程,而無須分別對FPGA編程。此外,全新仿真功能能夠在電腦上驗證FPGA應用,從而大大縮短了在編譯上消耗的開發(fā)時間。LabVIEW 8.6還提供了全新IP開發(fā)及集成特性,包括全新快速傅立葉變換(FFT) IP核,實現頻譜分析等功能,為機器狀態(tài)監(jiān)控及RF測試應用提供了更強的性能;全新的器件級IP(CLIP)節(jié)點,可便捷地將已有或第三方的IP導入LabVIEW FPGA,提升LabVIEW平臺的開放性。
隨著無線技術的發(fā)展,工程師們已經可以實現異地測量等應用。LabVIEW 8.6與無線技術的配合,能將數據采集應用擴展到新的領域中,如環(huán)境及建筑監(jiān)測等。LabVIEW圖形化編程的靈活性及無處不在的Wi-Fi網絡構架能將無線連接融入全新或已有的基于PC的測量及控制系統中。
在最新無線數據采集設備及超過20家第三方無線傳感器驅動的支持下,LabVIEW 8.6作為獨立的軟件平臺,簡化了分布式測量系統的編程過程。在LabVIEW 8.6中,無需作代碼修改即可便捷地通過NI Wi-Fi 數據采集 (DAQ) 硬件來配置數據采集應用。同時,LabVIEW 8.6中全新的3-D可視化工具能夠集成遠程測量與設計模型,加速設計驗證的整個過程。
當操作人員和系統間持續(xù)的連接與訪問越來越普遍時,工程師希望可以在任一位置都能通過網絡來與系統進行交互。LabVIEW 8.6允許將LabVIEW應用轉化成電腦和實時硬件上的網絡服務器(Web Service),從而能在任何網絡驅動的設備上連接,如智能手機、PC機等。通過這一特性,工程師能夠采用標準網絡技術
]]>輔助駕駛系統可提供基本的安全功能,如增加紅外(IR)相機來提高觀察能力。更為先進的設計還可利用范圍廣泛的傳感器來提醒潛在的危險情況,從而使車輛可意識到周圍的交通情況、車道和行駛方向以及可能的碰撞目標。最終的目標是車輛能夠自動對這種信息做出反應,為司機提供信息以及特殊情況下的車輛控制能力,從而可保證乘客的安全。例如,有些最新的卡車中安裝了視頻攝像機來監(jiān)視前面的道路情況。如果車輛在沒有使用指示燈的情況下改變行駛路徑,比如可能是由于司機太疲勞了,那么系統就會通過車內的揚聲器給出聲音告警。
通過消除繁瑣的駕駛動作,輔助駕駛還可提供更高的舒適水平。例如,傳統的巡航控制允許司機設定一個固定的行駛速度,同時在需要時可手動控制。而現在的汽車則提供自動巡航控制(ACC)功能,可以自動控制油門和剎車來適應前面車輛的速度,從而與其保持安全距離。如果前面的車輛加速開走或改變行駛路徑,ACC會自動返回傳統巡航控制的預設速度。
輔助駕駛系統還有希望利用所謂的“電子牽引裝置”來提高交通效率。例如,車隊的領頭卡車由司機手動駕駛,但后隨的卡車則自動駕駛。除了減輕司機的許多負擔以外,卡車間的距離也可大大縮短,因為電子響應速度更為迅速。這樣不僅可節(jié)約完整的道路面積空間,而且由于前面車輛的后向氣流的影響,還要節(jié)約燃料。
另一種新興的安全技術稱為“被動式乘員識別系統”。美國政府要求從2006年開始的所有新款汽車都必須能夠根據乘員的體型來打開氣囊。此類系統使得保護氣囊能夠“智能”打開或收縮。這種基于乘員體重的系統將可幫助汽車制造商滿足最近公布的《美國聯邦車輛標準安全法規(guī)》FMVSS-208的要求。該法規(guī)要求氣囊必須能夠針對不同乘員的體重更為有效地打開。從2004年開始,每家汽車制造商在美國銷售的車輛中有35%必須裝備先進的氣囊系統,這一數字到2006 年將提高到接近100%。較為簡單的系統采用安裝在乘員座墊下的體重傳感器技術來實現。高級乘員識別算法和快速信號處理使汽車氣囊控制器可根據不同的情況來打開或收縮乘員氣囊,從而可大大提高乘員安全性并降低修理成本。更為高級的系統則采用安裝在車內的相機來檢測和識別乘員,同時在算法上考慮到乘員調試及離氣囊的距離來判斷事故發(fā)生時氣囊打開的時間、速度和程度。
Xilinx FPGA在輔助駕駛系統中的應用
圖2給出了賽靈思現場可編程門陣列(FPGA)應用于ACC輔助駕駛系統的一個概念性框圖。
系統劃分為超高速輸入處理和相對低速的傳感器輸入和輸出控制信息,每個部分都在相應處理器(例如,一個Xilinx MicroBlaze 32嵌入式軟內核處理器或者Virtex-II Pro FPGA中嵌入的IBM PowerPC)的控制之下。高速部分專用于對安裝在車輛前面的視頻攝像信息進行實時處理。由于應用(防碰撞、緊急處理和告警)本身的特點,實時處理絕對是非常關鍵的。通常需要兩個或更多相機來獲得立體圖像,這樣就可以在FPGA中計算出圖像的深度(直接與前面物體的實際距離相關)。結合雷達和激光測量,以及來自陀螺儀和車輪傳感器的運動檢測信息,可以相當準確地計算出車輛周圍的情況和行駛路線。利用完全靈活的FPGA來代替成品視頻組件,設備制造商可容易地開發(fā)出區(qū)別于競爭廠商系統性能的、獨特的、優(yōu)化的邊緣檢測、圖像深度和增強算法。實時捕捉并處理這些信息需要使用計算密集的數字信號處理(DSP)算法。然而,軟件處理無法滿足性能要求;盡管傳統DSP處理器也是一種選擇,但通常需要多片器件才能完成如此高速的任務。甚至ASSP視頻處理器也無法與 Xilinx FPGA(也稱為XtremeDSP處理)的極高速DSP性能相比。在視頻處理完以后,決策樹機制可以劃分為針對緊急算法(如緊急的防碰撞過程)的硬件部分,以及用于行駛路徑偏差等的聲音告警的處理器軟件部分。將速度關鍵的處理過程劃分到FPGA硬件中還可以對實時速度進行測試,而這對于軟件是不可能的。
XtremeDSP 實時圖像處理
那么為什么Xilinx FPGA能夠提供比傳統DSP更快的視頻處理性能呢?最根本的原因是由于FPGA結構能夠實現數據的并行處理。來自Xilinx的最新Vir tex- Pro系列器件還集成有嵌入式高性能乘法器模塊陣列,可以進一步提高圖像處理的能力。與此相對比,DSP處理器順序執(zhí)行指令和數據,并且以串行方式處理他們。因此FPGA可配置為能夠并行執(zhí)行多個操作(在單個時鐘周期內)的乘法累加(MAC)單元陣列,而不是像傳統的DSP中那樣需要多個時鐘周期才能在一個或少量MAC單元中執(zhí)行完畢。
Xilinx FPGA還具有可利用準確的MAC陣列來滿足計算要求的額外優(yōu)點。這些特性對于完成圖像計算非常理想。這樣就可對圖像中的多個像素簇(如離散余弦變換(DCT)的宏塊)進行并行計算,而不必依序掃描整個圖像。FPGA性能的提高還帶來更多額外好處,例如,緩沖像素值所需要的存儲器數量可更小,因為現在可實時處理。
除了實時性能以外,Xilinx FPGA的可重編程能力還提供了優(yōu)異的系統靈活性,支持算法升級(即使在部署以后)。這一點非常重要,因為目前的輔助駕駛系統仍然處于早期研發(fā)階段。隨著邊沿和目標檢測算法的不斷改進,可在數分鐘中內完成硬件升級,而且不需要重新設計電路板。
利用可編程外設橋接汽車網絡
隨著汽車中演化出真正小型網絡,設備制造商必須確定在眾多的網絡協議中哪種標準將是最成功的,或者哪些標準能夠為自己帶來最大的好處。不同的網絡技術被用來滿足汽車中的不同需要,從駕駛艙內的多媒體范圍(面向多媒體的系統傳輸,MOST)直到汽車控制網絡(如FlexRay)。圖2中選擇了一種預驗證的控制區(qū)域網絡(CAN)接口內核作為例子。
可應用于車內的一種此類新興網絡協議就是藍牙。藍牙無線技術是一種用于移動設備和WAN/LAN接入點的低成本、低功耗的短距離射頻技術。這種源于計算和電信行業(yè)的標準描述了手機、計算機和PDA等設備之間如何利用一種短距離無線連接實現方便的互連。
例如,駕駛員可以利用藍牙無繩耳機與口袋中的手機通信。因此可避免司機分心并提高了安全性。汽車工業(yè)成立了一個特殊興趣組(SIG)來定義藍牙汽車標準。該特殊興趣組的成員包括汽車多媒體接口協作組織(AMIC)、寶馬、戴姆勒-克萊斯勒、福特、通用汽車、豐田汽車以及大眾汽車有限公司等。藍牙在汽車中應用的一個例子Johnson Controls公司的免提手機系統“BlueConnect”,該系統允許司機在雙手扶住方向盤的情況下通過支持藍牙功能的手機保持聯系。
然而,藍牙器件的長期支持還存在問題,同時車內環(huán)境噪聲對于藍牙設備工作的影響也需要認真考慮。轎車和其他車輛的壽命要比消費類產品或手機長得多,因此芯片制造商必須解決由此而帶來的支持和服務生命期不匹配的問題。然而,最近在底特律舉辦的Convergence 2002展會上,克萊斯勒集團展出了應用了藍牙技術的汽車。
與采用ASSP相比,采用FPGA的最大好處之一是允許工程師設計出精確匹配系統要求的接口和外設。在開發(fā)的早期階段試圖連接到不同的汽車網絡時,這一點特別有用。當試圖快速將產品推向市場時,芯片組或ASIC重新設計即成本昂貴又耗費時間。在標準實現的早期,如果網絡協議規(guī)格有所變化,為了支持最新的版本,在使用FPGA的設計時只需要簡單地修改軟件,然后再重新下載FPGA硬件配置就可以了。甚至還要以利用Xilinx IRL(因特網可重配置邏輯)通過廣域網來完成這一點,因此不需要成本高昂的派工費用或額外的人力就可以通過遠程維護完成硬件修改。
針對汽車應用的Xilinx IQ解決方案
為滿足汽車電子設備設計人員的需要,賽靈思(Xilinx)公司推出了一系列支持擴展工業(yè)溫度范圍的新器件。稱為“IQ”范圍的這些新器件包括Xilinx 目前符合擴展溫度級(Q)要求的現有工業(yè)級(I)FPGA和CPLD(表1)。符合新的IQ溫度范圍要求的第一批器件是密度范圍從5K門至3K門的 Spartan-XL 3.3V FPGA,以及36和72宏單元的XC9500XL 3.3V CPLD。在未來的幾個月時間里,IQ溫度范圍器件將會擴展包括密度高達30萬門的FPGA器件,以及密度高達512個宏單元的CPLD器件,如表2所示。
結論
輔助駕駛系統的開發(fā)和應用需要高性能圖像處理,同時又不希望犧牲在目標檢測和汽車網絡技術研發(fā)的早期階段所需要的靈活性。采用Xilinx FPGA作為此類系統的核心為業(yè)界提供了最佳的DSP性能和無與倫比的網絡連接標準支持能力,同時為系統設計師提供了一個完全靈活的設計平臺。通過可實時工作的此類系統,為駕駛人員提供緊急駕駛告警或輔助車輛控制功能就成為可能,從而可大大提高車輛駕駛和乘座的安全性]]>
正如我在《科技以人為本 - CES結語》一文中講的,科技在近20年里發(fā)生了翻天覆地的變化,背后的推動主要來自于半導體技術的飛速發(fā)展,其中最大的革命是天才的人們通過模數變換,把自然界的一切模擬量變換到數字域,在數字域里用我們5千年來練就的功力 - 數學來描述并處理模擬的世界,在數字邏輯的基礎上人們又發(fā)明了基于指令的計算、數字信號處理等技術,于是有了我們今天的壓縮視頻、數字通信、無線網絡、互聯網等等,可以說“數字”是當今半導體科技的主旋律,我們正處于一個“數字時代”,正如本年度的CES也把主旋律定義成了“數字經濟”。從事電子技術的同仁們都知道,數字邏輯的基本單元就是“門”,由眾多的“門”構成各式各樣無論多么復雜的邏輯功能。FPGA - “現場可編程”“門陣列”,也就成了數字領域的“樂高”,用它可以搭建出任意的作品。
FPGA的演進
讓我先來回顧一下歷史。1989年我第一次接觸到電路板的時候,上面密布著一系列的TTL、CMOS芯片,一顆14~20只管腳的芯片中一般只有4-6個簡單的“門”,十幾個芯片的大板子也就完成尋址、譯碼之類的功能,使用起來是非常的痛苦,如果要修改邏輯,只能用手術刀切割電路板并進行飛線。94年的時候我開始使用GAL
在前后十年多的時間里,可編程邏輯器件尤其是FPGA從結構、容量、速度、編程軟件、服務模式等方面都有了巨大的變化,小到最基本的數字邏輯,大到復雜的通信網絡、視頻編解碼系統乃至ASIC原型設計,無處不見FPGA的身影。今天如果一個研發(fā)用的電路板上沒有FPGA,這個研發(fā)項目的技術含量基本不高;如果一個工程師不會使用FPGA,他根本不好意思跟別人說自己是做硬件的;如果一個理工科院校還沒有FPGA的課程,這個學校一定十分不靠譜,需要Xilinx大學計劃的幫助。
FPGA的優(yōu)勢:
根據應用的不同,設計者所采用的解決方案也會不同,在大規(guī)模數字芯片中比較典型的技術主要有:微處理器、DSP、專用集成電路ASIC等,相對于這些技術的應用來講,FPGA有什么優(yōu)勢呢?
1. 微處理器:今天的微處理器(包括微控制器)品種繁多,結構也各不相同,從4位、8位、16位、32位到64位,有8051,PIC,RISC、ARM、MIPS、Xtensa以及X86等,他們大多有豐富的接口同各種外設進行連接,通過軟件執(zhí)行不同的進程,從而完成一定的任務,并將控制命令或結果進行輸出。可以說通過軟件編程微處理器可以做任何事情,但是致命的缺點就是速度有限,在外部時鐘的節(jié)拍下順序執(zhí)行一條條的指令,不能并行處理,因此微處理器廠商只能玩命提高芯片的速度(比如Intel的芯片時鐘在2GHz以上,ARM已經在600MHz以上),對于更復雜的任務只能多放幾個兄弟在里面一起干活,也就是今天的多核技術。由于一般稍微復雜一些的系統都會用到微處理器用于輸入輸出、多進程處理以及網絡通信等,很多滿足一定性能需求的通用微處理器成本較低,因此被廣泛采用。現在微處理器領域最熱門的技術術語無疑就是 “嵌入式系統”了,但我可以負責任地講,大多數人對“嵌入式系統”的理解是片面甚至是錯誤的。有些公司為了商業(yè)利益把嵌入式系統以“皇帝的新裝”模式進行大規(guī)模地忽悠,導致人們幾乎把“嵌入式系統”同某一種IP類型畫上了等號,這個行業(yè)涌現出了大批的根本不懂嵌入式系統的嵌入式系統工程師。
2. DSP
3. ASIC
4. FPGA: 它比較明顯的缺點就是相對來講成本較高,主要用于研發(fā)過程中或者市場量不會很大,FPGA在系統的整體價格中不敏感。一顆FPGA芯片的價格從低于1美元到幾千美元不等,當然這是可以理解的,畢竟靈活性是靠高度的冗余帶來的。它的好處是其它任何一種技術無法比擬的 - 它幾乎可以做任何事情,你可以用它搭建多個微處理器,用它構建自己的乘、除法單元做出幾個DSP來,而且這些處理器、DSP可以同時干活,并行工作,與此同時您還可以利用芯片內部未用的資源做很多輔助的功能,可以說是高度的靈活。
以一個應用為例,今天的汽車電子也是以人為本,該領域的一個重要的技術熱點就是“司機幫助(DA)”系統,它由超聲、雷達、照相機以及激光等多種不同的傳感器構成,這些不同的傳感器在不同的時刻或者同一時刻把相應的信號采集下來,發(fā)往中央處理單元進行識別、運算、做出判斷,幫助司機在倒車、高速行駛以及夜間行駛的時候能夠對周圍的環(huán)境在最短的時間內做出準確的判斷并做出一系列的安全保護動作。如果采用微處理器或DSP對多傳感器的信號進行處理,它們無法并行執(zhí)行多個任務,并且同其他系統進行互聯,因此就會造成系統的處理時間延遲,可靠性差,從而導致事故無法及時避免。如果采用ASIC呢?隨著用戶對功能要求的不斷增加,對性能要求的不斷升級,也就要求算法要不斷的改進,顯然采用ASIC無論從靈活性還是成本上都是不合算的。圖1是Xilinx專為汽車電子開發(fā)提供的功能模塊,圖2為在一顆Spartan-3E FPGA中針對“司機幫助”集成了很多的功能 。
圖1 FPGA平臺能夠支持的“司機幫助”系統功能
圖2 采用Xilinx Spartan-3E的“司機幫助”解決方案
FPGA的設計:
FPGA的功能越是強大,對設計的要求也就越高,畢竟有那么多的管腳需要跟其它芯片連接起來,有那么多的功能要一行一行地采用邏輯寫出來,遠遠不是十年前處理門級電路的時候了。雖然今天大多數用過FPGA的工程師已經對這個痛苦的過程深有體會,我還是把他們列舉在此:
1. 電路板設計:
現在的電路板設計動不動就是4層板、6層板甚至更多層,芯片的封裝也變得稀奇古怪,什么QFN、BGA等等,如果發(fā)現了連接不對想手工修改,拿著烙鐵都找不到往哪里燙,根本沒有露出來的管腳。尤其是FPGA芯片, 256個管腳的BGA封裝都算照顧你了,如果再增加一些功能,容量再大一些,一不留神就到1000多個管腳去了,光做原理圖中的符號就要折騰你三天,完了還要拿著放大鏡不斷地檢查,否則做回來的電路板極有可能是廢的。這還不算,等你布局、布線的時候你會發(fā)現很多的線都是扭著的,一是難布,二是電氣性能也不好,好在FPGA的管腳是可以重新配置的,修改一下管腳的定義就可以讓芯片之間的聯線能過做到最優(yōu)。
當然系統的速度高了,對高速數字設計方面的知識要求就是必須的了,這里面有一個詞叫“信號完整性”,有幾位美國大牛在這方面很有研究,其中有不少他們的著作翻譯成中文了。如果你想真的理解并能夠靈活應用,好好回爐去學扎實電磁場理論,不懂電磁理論,就不可能做好高速數字設計。FPGA支持各種高速串、并行總線并在很多系統中要和高速的數據、時鐘進行連接,如果信號被你給搞得不完整了,整個系統性能會大大降低甚至不干活。
一般的系統都會有一個需要大電流的Core電壓(1.2V或1.8V等,取決于工藝)和一個需要小電流的接口電壓(一般是+3.3V),并且有多組不同的地。除了這些對工程師的布線提出挑戰(zhàn)之外,還必須重視的一個部分就是鎖相環(huán)(PLL/DLL),這個部分的布線是相當的關鍵,一旦有問題,整個系統的性能就會大打折扣,雖然數字的電路不是0就是1,可它就跑不快了。
2 邏輯設計:
最初用PLD/FPGA的時候還都是采用圖形輸入法,直觀而原始。現在FPGA的用戶基本都在采用更高級的語言 - VHDL或Verilog,這種語言高級得如同C,用起來非常容易。但是您千萬不能把它當C來使喚,畢竟硬件和軟件還是不同的。4年前在我做硬件工程師的時候,一個擅寫DSP軟件的兄弟寫了一段FPGA的代碼,他花了整整一頁的篇幅實現了一個用硬件的思路只要4句話就可以完成的功能,搞得我苦笑不得。在這里面要時刻注意的是,FPGA內部多個功能模塊都是可以并行操作的,如果用程序的思路去寫,基本上會讓他們排著隊串著出來,當成DSP用了。
3 充分利用現有的資源:
無需爭議,今天你已經不可能徒手把一個Spartan-3E中哪怕最小的系列給填滿了,重新寫一個I2C接口,重新做一個以太網的MAC作為鍛煉還可以,在實際的項目中每個都自己去寫是不可取的,如何利用現有的資源是非常重要的。首先在每個人的設計工作中要注意積累,把曾經用得不錯的功能模塊認真完善后寫好文檔以便今后自己或他人使用;再次FPGA的廠商都在配套的軟件中內嵌一些免費的功能模塊,根據自己的需求可以靈活地進行配置使用。當今互聯網時代,信息分享成了主旋律,因此你可以方便地在一些開源的社區(qū)中找到自己需要的東西,比如在www.openhw.org社區(qū)中你就可以找到并下載很多其他FPGA同仁們開發(fā)并驗證過的功能模塊,如果有問題還可以在社區(qū)內同他們進行互動交流,咨詢等,要把這些先進的手段都用上。當然如果公司有財力,又需要在最短的時間內推出產品,您可以到FPGA廠商的網站上,那里陳列著琳瑯滿目的商用IP, 這些都是FPGA廠商會同他們認證過的聯盟廠商共同推出來的,您可以放心地使用。圖3為Xilinx公司為消費電子領域的“數字顯示屏”提供的系列IP示例。
圖3 Xilinx同聯盟廠商提供的用于“數字顯示屏”的系列IP
FPGA的改進:
技術仍在不斷發(fā)展,而且是以更快的步伐。FPGA在容量、功能和速度上的提高帶給我們今天年輕人的壓力越來越大,那么多的專業(yè)知識需要學習,那么多的設計技巧需要掌握,那么多的系統功能需要實現,對用戶的挑戰(zhàn)同樣也是對FPGA廠商的挑戰(zhàn),如何能夠讓用戶在最短的時間內設計出滿足其性能需要的產品是FPGA廠商面臨的最主要的問題,同時也影響著他們服務模式的改變,在此列舉出我認為目前FPGA廠商需要注意的一些問題。
Altera公司產品和企業(yè)市場副總裁Vince Hu評論說:“FPGA與處理器的組合應用迅速擴展到在嵌入式系統設計中開發(fā)新的定制產品。通過嵌入式計劃,Altera使汽車、工業(yè)、軍事和無線等市場的設計人員能夠在單一設計流程中,方便的利用處理器、操作系統以及IP支持等輔助系統,降低了系統總成本,更迅速的將產品推向市場,提高了系統的靈活性。”
作為該計劃的一部分,Altera將繼續(xù)拓展目前的嵌入式合作伙伴計劃,聯合ARM、Intel和MIPS技術公司以及FPGA業(yè)界的多個合作伙伴。此外,Altera將與他們協作,增強設計流程,支持越來越多的FPGA嵌入式處理產品走向市場。
Intel最近全面發(fā)布了即將推出的基于Atom的可配置新處理器。這一處理器在多芯片封裝中含有Intel Atom E600系列以及配對的Altera? FPGA。對于希望采用專用I/O或者加速硬件的用戶而言,這進一步提高了他們的靈活性,還支持開發(fā)人員迅速應對需求的變化,從而突出其設計優(yōu)勢。
Intel嵌入式通信組副總裁兼總經理Doug Davis說:“靈活性是嵌入式設計人員的關鍵,而FPGA技術提供了更多的選擇。Intel最近發(fā)布了集成Altera FPGA與基于Intel Atom處理器的多芯片封裝產品,繼續(xù)為嵌入式開發(fā)人員提供靈活的智能解決方案。”
Altera還透露上半年與ARM有限公司簽署了協議,授權包括Cortex-A9微處理器在內的多種技術。Altera將在28nm FPGA技術中提供集成了增強Cortex A9處理器子系統的產品。Altera將在2011年發(fā)布這些基于ARM處理器的器件的詳細信息。
ARM處理器部門市場副總裁Eric Schorn說:“ARM認識到FPGA業(yè)界的重要性,非常希望與合作伙伴一起協作,以滿足嵌入式設計人員對靈活性的需求。ARM在低功耗、高性能處理器IP上的領先優(yōu)勢與Altera的專業(yè)FPGA技術相結合,使我們能夠采用公共軟件流程來進一步提高靈活性,幫助軟件開發(fā)人員和硬件設計人員加速各種應用的開發(fā)。”
Altera還進一步擴展了軟核處理器系列產品,即將在2011年上半年推出基于MIPS技術公司MIPS32處理器體系結構的MP32軟核處理器。MP32是Altera、MIPS技術公司以及主要用戶過去幾年密切協作的結果。它針對Altera器件完善了Altera Nios II嵌入式處理器以及合作伙伴軟核CPU系列產品,極大的豐富了FPGA可以使用的操作系統和應用程序。
MIPS技術公司市場副總裁Art Swift說:“我們非常高興的看到,通過MIPS32體系結構許可,Altera提供MP32軟核CPU,大幅度增強了當今多核設計體系結構的靈活性。隨著處理器和可編程邏輯集成的加速,在Altera平臺上實現MIPS32體系結構是嵌入式設計人員很好的選擇。”
本季度末,Altera將提供Qsys系統集成工具,它是Quartus II開發(fā)軟件的一部分。采用業(yè)界首創(chuàng)的FPGA優(yōu)化芯片網絡技術,Qsys能夠提供存儲器映射和數據通路互聯,使Altera SOPC Builder工具的性能幾乎提高至兩倍,同時支持業(yè)界標準IP接口,例如,AMBA。Qsys將采用使用方便的SOPC Builder界面,支持與現有嵌入式系統移植的后向兼容。而且,這一高級互聯技術將支持分層設計、漸進式編譯以及部分重新配置方法。
]]>“Table 3”是在業(yè)界等到公認的美國高級電信標準協議(STSC)定義的廣播格式一覽表。正如表中所看到的那樣,設備制造商可進行眾多的選擇-高分辨率(HD)還是標準分辨率(SD),16:9還是4:3,逐行還是隔行掃描等。雖然也有ASSP(特定應用標準產品),但經常是每種標準需要不同的芯片。FPGA解決方案可容易地支持超過HDTV要求的數據傳輸速率,這意味著一個器件可以支持所有這些格式,只需要根據設備的需要進行重新編程就可以了。這可減少企業(yè)的用料清單項目,同時還排除了ASSP供應商可能存在的供貨風險。
需要進行標準選擇的另一個例子是色彩空間變換。圖像從照相機采集進來以后就利用壓縮算法對其進行處理,再通過后期制作直到在電視機顯示出來的過程中也是如此。壓縮算法利用了這樣的事實,即不必傳輸一幅圖像的所有色彩信息就可得到滿意的效果。以RGB(紅、綠、藍)格式進行圖像處理是可行的。在RGB格式中,每一像素以對應每一原色的三個8或10位字來定義。但由于人眼對光線頻譜中某些部分比其它部分反應要小,因此可以利用亮度或(Y)以及色差信號(如CrCb)來表示圖像。這樣做的好處是需要較小的存儲和數據帶寬。因此需要一種機制來進行不同色彩格式間的轉換,這也稱為色彩空間變換。一旦知道從一個色彩空間向另一個色彩空間映射的系數,用硬件實現這些電路就非常簡單。
例如,在數字電視系統中,YerCb色彩空間可按下式轉換至RGB色彩空間:
R\ = 1.164 (Y-16) + 1.596(Cr -128)
G\ = 1.164 (Y-16) - 0.813 (Cr -128) - 0.392(Cb-128)
B\ = 1.164 (Y-16) + 1.596 (Cr-128)
其中R\G\B\是伽馬(Gamma)校正RGB數值。由于CRT顯示器中,接收到的控制信號幅度和輸出強度間是非線性關系。顯示器前的伽馬校正信號可使接收信號幅度和輸出強度的關系線性化。輸出增益也限制在一定的閾值,從而降低圖像暗部由于傳輸引入的噪聲。有多種可能的實現方法,可利用存儲器、邏輯或嵌入式乘法器在FPGA中實現所需的乘法功能。
當需要在大量色彩空間之間進行轉換選擇時,采用可編程色彩空間變換器的優(yōu)點非常明顯。正如此處所示的YCrCb 與RGB變換一樣,YUV以及YPrPb 采用與此類似的算法,只是系數有所不同。雖然有標準的色彩空間,但不同設備間的要求有許多不同的地方。高分辨率圖片甚至采用與標準定義不同的色彩空間,但具有可編程的變換系數的設備可以容易地支持任何輸入分辨率。同時如果需要的話,多通道色彩空間變換支持也可以做到,而如果不采用可編程邏輯的話,這通常需要多塊ASSP。當然,利用FPGA器件,系統架構還可根據應用調整相應的算法,從而使性能、效率或兩者同時實現最大化。
FPGA經常被大型數據和電信企業(yè)廣泛用作網絡接口設備。可編程架構非常適合協議管理和數據流格式處理,而FPGA提供的高速差分I/O如LVDS,使FPGA可以非常快的速度向片上讀入和向片外輸出數據。FPGA還可用于局域環(huán)境,如家庭網絡。歐洲DVB(數字電視廣播)聯盟最近采用IEEE1394高速串行總線作為數字電視產品的標準連接方式。無線標準,如IEEE802.11 和 HiperLAN2也被提議作為擁有多臺電視的家庭網絡的連接方案。
隨著世界許多地區(qū)高分辨率廣播的出現,視頻信號處理要求極大地提高了。例如,采用1920×1080分辨率、24位像素和每秒30幀逐行掃描的高分辨率電視機將需要約1.5Gbps的總的未壓縮帶寬。即使在還沒有實際進行高分辨率圖像廣播的地區(qū),在直到后期制作的所有階段中,采用的也是高分辨率圖像。
現在最新的可編程邏輯器件具有多個可支持此類數據速率的LVDS(低壓差分信號)I/O,即使在針對消費市場的低成本器件中也有這樣的I/O支持。這意味著未壓縮的視頻數據可輸入和輸出器件并進行實時處理。HDTV速率一級的實時視頻處理允許設計人員減少需要的外部存儲器數量。目前,由于在設計中視頻信號處理器部分成為瓶頸,因此現有的數字電視系統中經常采用多個幀存儲和數據緩沖器。利用FGPA的并行信號處理能力意味著更小的,甚至單幀存儲即可,而數據緩沖器則可完全省掉。標準DSP在性能方面的局限導致不得不開發(fā)更為專用的芯片,如媒體處理器,來克服這些問題。然而,事實證明這些器件除了在范圍極窄的一些應用中,都有太不靈活的缺點,同時還有性能瓶頸存在。而FPGA器件則可以通過定制,在利用率和性能方面提供最大的效率。設計人員還可以在設計面積和速度之間進行折衷,并且可以比DSP低得多的時鐘速率完成給定的功能。
如前所述,FPGA過去僅用于專業(yè)的廣播系統中,但摩爾定律意味著他們正逐漸應用于大批量消費產品中。以數字電視為例,其中機頂盒功能完全集成到電視中,因此數字電視可接收數字廣播。通常這都是通過標準天線接收免費的無線信號,但未來的產品將允許接收來自電纜、衛(wèi)星或DSL線路傳輸的信號。FPGA可應用于數字電視機內的許多部分,1所示。做為標準芯片組間的“聯結邏輯(glue logic)”一起是FPGA的強項,但許多圖像處理任務(如色彩空間變換)以及網絡接口(如IEEE 1394)現在也可在低成本可編程邏輯器件內實現。
這一將圖像處理任務用FPGA完成的趨勢有一個重要驅動力:來自業(yè)界所稱的“數字融合”。目前產生了這樣一些需求,即通過極為有限的傳輸信道(如無線)發(fā)送大帶寬的視頻數據,同時還要保持可接受的服務質量(QoS)。這導致對如何改善錯誤校正算法、壓縮和圖像處理技術進行范圍更為廣泛的研究,而其中相當一部分工作是圍繞利用FPGA器件進行的。
采用FPGA,設計人員可以使自己的標準兼容的系統與競爭對手的產品保持差異化。以MPEG-2壓縮方案為例,可以將MPEG處理器負責的MPEG標準算法中的DCT(離散余弦變換)部分卸載至FPGA器件中進行處理,從而增加帶寬。DCT及其反變換可利用FPGA高效地實現,而且已經有經過優(yōu)化的IP核可直接應用到基于MPEG的設計之中。但MPEG編碼方案中還有許多未定義的模塊(如運動預測)。通過在FPGA結構中集成用于這些模塊的專有技術和標準的象DCT這樣的功能,就可以創(chuàng)造出可提高處理帶寬并達到更高圖像質量的低成本的單片解決方案。通過避免系統僅依賴于標準ASSP解決方案,企業(yè)就不再會有被市場認為僅能提供有限的幾種類似解決方案的危險。
FPGA還可使您的產品更快地推向市場,并可在現場安裝后保持為您產生更多營收的能力。多數FPGA都基于SRAM技術,從而在開發(fā)的各個階段都可以容易地對器件進行重新編程。這使系統的調試更為簡單,而且還意味著如果需要的話,微小的改變也可容易地整合到產品中去。這有可能會由于客戶要求的改變,也由可能是由于標準的新版本或修正。
]]>
例如,在為產品選擇 FPGA 時,功耗的考慮變得越來越重要。很可能下一代設計會需要在功耗預算不變(或更小)的情況下,集成更多的特性和實現更高的性能。
在本文中,我將分析功耗降低所帶來的好處。還將介紹 Virtex-5 器件中所使用的多種技術和結構上的革新,它們能提供功耗最低的解決方案,并且不會在性能上有任何折扣。
降低功耗的好處
低功耗的 FPGA 設計所帶來的優(yōu)勢不僅是能滿足器件工作的散熱要求。雖然滿足元件指標對于性能和可靠性十分重要,但如何實現這一點對于系統成本和復雜性都有著巨大的影響。
首先,降低 FPGA 的功耗使你能夠使用更便宜的電源,這樣的電源使用的元件數量較少,并且占用的 PCB 面積也較小。高性能的電源系統的成本通常為每瓦0.5到1美元。低功耗的 FPGA 直接降低了系統的整體成本。
其次,由于功耗直接與散熱相關,低功耗使你能夠使用更簡單、更便宜的熱量管理解決方案。在很多情況下,設計者將不再需要散熱器,或者只需要更小、更便宜的散熱器。
最后,由于低功耗工作意味著更少的元件和更低的器件溫度,因此將提高整個系統的可靠性。器件工作溫度每降低10℃,就相當于元件壽命提高了兩倍,因此對于需要高可靠性的系統而言,控制功耗和溫度十分重要。
功耗:挑戰(zhàn)和解決方案
FPGA (或任何半導體器件)中的總功耗等于靜態(tài)功耗和動態(tài)功耗之和。靜態(tài)功耗主要由晶體管的泄漏電流引起,即晶體管即使在邏輯上被關斷時,從源極“泄漏”到漏極或通過柵氧“泄漏”的小電流。動態(tài)功耗是器件核心或 I/O 在開關過程中消耗的能量,與頻率相關。

圖1:85℃時的靜態(tài)功耗比較
靜態(tài)功耗
在縮小晶體管尺寸時(例如,從90納米到65納米),泄漏電流將會增大。新工藝結點所使用的短溝長和薄柵氧使電流更容易從晶體管的溝道區(qū)或通過柵氧泄漏。
在90納米 Virtex-4 系列產品中,Xilinx 公司使用了“三柵極氧化層”的工藝技術,向 Xilinx 電路設計者提供了一種強有力的阻止漏電工具。在前幾代 FPGA 中,使用兩種柵氧厚度:薄柵氧用于 FPGA 核心中高性能、低工作電壓的晶體管,而厚柵氧用于 I/O 模塊中尺寸較大,需要承受大電壓的晶體管。簡單地來說,“三柵極氧化層”指增加一種中間厚度柵氧的晶體管,它的漏電比薄柵氧的核心晶體管要小得多。
“中間柵氧”的晶體管用在器件核心外圍非關鍵性能的電路(像設置存儲器)或不需要對變化的柵壓進行快速開關響應的電路(像傳輸門)中。薄柵氧、漏電最大的晶體管只保留在需要快速開關速度的路徑部分。結果,總的器件漏電被大大減小,同時性能仍能比上一代 FPGA 有很大提高。
三柵極氧化層工藝使 Virtex-4 器件比競爭性90納米 FPGA 在靜態(tài)功耗上平均減少了超過70%。這一結果非常成功,因此 Virtex-5 系列產品中大量使用了這一技術,在65納米工藝結點上降低漏電。
雖然業(yè)界預測65納米器件的靜態(tài)功耗將會有大幅度提高,但是圖1顯示了三柵極氧化層工藝使65納米 Virtex器件在最壞(溫度最高)工作條件下達到了與尺寸相當的90納米 Virtex-4器件相同水平的靜態(tài)功耗。因此,Virtex-5 系列產品和競爭性高性能 FPGA 產品相比,在靜態(tài)功耗方面具有真正的優(yōu)勢。
動態(tài)功耗
動態(tài)功耗為65納米 FPGA帶來一些其它方面的挑戰(zhàn)。動態(tài)功耗的公式為:
動態(tài)功耗 = CV2f
其中C是結點開關時的電容,V是電源電壓,f是開關頻率。65納米工藝節(jié)點使 FPGA 的邏輯能力和性能比傳統器件有了顯著提高,也就是說更多的結點工作在更高的頻率上。如果其它方面的條件不變,動態(tài)功耗將會增大。
但是,對于65納米工藝節(jié)點的動態(tài)功耗而言,也有一個好消息:FPGA 核心的電源電壓(V)和結點電容(C)通常在每一代新工藝中都會下降,從而使得動態(tài)功耗比上一代 FPGA 有所下降。
Virtex-5 器件中,核心電源電壓(VCCINT)從Virtex-4 中所使用的1.2V下降到1.0V。由于寄生電容變小(與更小的晶體管相關),以及邏輯塊間的互聯線長度變短、電容變小,使結點電容減小。此外,Virtex-5 器件在金屬互聯層之間使用了一種介電常數較低的材料。
Virtex-5 器件的平均結點電容比Virtex-4 器件大約減小了15%。加上電壓降低帶來的好處,至少相當于將 Virtex-5 器件的核心動態(tài)功耗降低了35-40%。
除“工藝尺寸縮小”到65納米所帶來的固有的35-40%的動態(tài)功耗降低外,Virtex-5 器件的架構創(chuàng)新,還能進一步降低每個設計的功耗。大多數可增加動態(tài)功耗有的結點電容,是由邏輯功能間的互連線引起的。新型 Virtex-5 架構在兩個方面從根本上減小了連線電容:
Virtex-5的可配置邏輯模塊(CLB) 是基于6輸入查找表(6-LUT) 邏輯結構的,在以前的器件中是使用4輸入查找表。這意味著在每個 LUT 中能夠實現更多的邏輯,相當于較少的邏輯級,從而降低了對邏輯功能之間大電容連線的需求。
Virtex-5 的互聯結構目前包括了對角線對稱的連線,意味著每個 CLB 與所有相鄰的模塊(包括處于對角線位置的模塊)之間都有直接的“單一”連接。當邏輯功能之間需要連接時,這一連接更有可能成為總電容最小的“單一”連接,而以往的互聯結構對于相同的連接問題可能會需要兩個或更多結點。

圖2: 計數器標準設計的動態(tài)功耗比較
6-LUT 結構和改進的互聯模式,通過降低平均結點電容來降低核心的動態(tài)功耗,效果遠遠超過僅使用65納米工藝所帶來的改進。圖2顯示了來自標準設計的核心動態(tài)功耗的測量結果,其中每個 Virtex-5 器件和 Virtex-4 器件中都有1024個8位計數器。這些實際的測量結果顯示,工藝和結構上的共同優(yōu)化所帶來的動態(tài)功耗的降低超過了50%。
硬IP模塊
Virtex-5器件中包含的硬IP模塊(專門用來實現一些常用功能的電路)的數量,超過業(yè)界其他任何一款 FPGA。相比使用通用 FPGA 邏輯而言,使用搭載這些模塊的 FPGA 設計來實現這些功能,可進一步降低功耗。
與 FPGA 結構不同,這些專用的模塊中只有實現所要求的功能必需的晶體管。并且沒有可編程的互聯,因此互聯電容最小。較少的晶體管和較小的結點電容能降低靜態(tài)和動態(tài)功耗。從而使這些專用模塊在實現相同功能的同時,功耗只有使用通用 FPGA 結構的十分之一。
除增加新型的專用模塊外,Virtex-4 器件中融合的很多模塊,在 Virtex-5 器件中都被重新設計,以增加新的特性,提高性能,降低功耗。例如,Virtex-4 系列中18-Kb 的 block RAM 存儲器在 Virtex-5 器件中被增加到了36-Kb;每個 block RAM 能被分成兩個獨立的 18-Kb 的存儲器,以便向下兼容 Virtex-4 的設計。
有趣的是,從功耗的角度來看,每個 18-Kb 的子模塊由兩個 9-Kb 的物理存儲陣列構成。對于大多數的 block RAM 配置,任何對于 block RAM的讀寫請求一次只需要訪問 9-Kb 物理存儲器中的一個。因此其余的 9-Kb 存儲器能在不被訪問時被有效地“關斷”。在過渡至65納米工藝所帶來的功耗降低的基礎上,這種結構又使功耗進一步降低了50%。這一對于9-kB 模塊的“乒乓”訪問是新的 block RAM結構所固有的,這就意味著使用這項功能不需要用戶或軟件來進行控制。它能動態(tài)并自動地進行,使所有使用 block RAM的設計降低了大量的功耗,并且不會影響模塊的性能。
Virtex-5 器件中專用的 DSP 元件也進行了大量的改進,以實現更多的功能,提高性能,并降低功耗。在片與片的比較中,新型的 Virtex-5 DSP 片的功耗比 Virtex-4 DSP 片的功耗降低了大約40%。這主要歸功于前面所討論的65納米工藝中電壓和電容的減小。
然而,由于 Virtex-5 DSP 片具有更強的功能和更廣泛的接口,許多 DSP 運算通過利用這些附加的功能進一步降低了功耗。在許多情況下,當使用新型 DSP 片的全部功能時,總功耗最高可降低75%。請記住即使你不是在設計一個 DSP 產品,也能使用 DSP 片來實現標準的邏輯功能(計數器、加法器、桶式移位器),這樣會比在標準 FPGA 邏輯中實現同樣的功能節(jié)省功耗。
最后介紹的經過改進的專用模塊是 Virtex-5 系列的 LXT 平臺,其中包括了幾吉位的串行收發(fā)機,能以高達 3.125Gbps 的速率工作。這些 “SERDES” 模塊在實現時著重考慮了低功耗需求。每個 Virtex-5 LXT 器件中的全雙工收發(fā)機在 3.125Gbps 的速度下的總功耗小于100毫瓦,與Virtex-4串行收發(fā)機相比降低了大約75%。

圖3:典型設計中現有 FPGA 的功耗比較
結論
Xilinx 公司悠久的創(chuàng)新歷史能夠追溯到20多年前第一塊 FPGA 的發(fā)明。因此 Xilinx 公司理所當然地成為第一家在深亞微米技術中將降低功耗作為首要任務的公司。與 Virtex-4 系列產品一樣,Virtex-5 器件也采用了一系列工藝和架構上的革新,力求在提供盡可能低的功耗的同時,仍然使性能提高30%或更多。
如圖3所示,Virtex-5系列產品的靜態(tài)功耗與 Virtex-4 器件相當,但比競爭性 FPGA 具有明顯的優(yōu)勢。作為唯一的65納米 FPGA,Virtex-5 器件核心的動態(tài)功耗比市場上其它高性能 FPGA 低至少35-40%。像新型 6-LUT 和對角線對稱的互聯等架構上的革新,使實際核心動態(tài)功耗進一步降低了50%或以上。此外,利用數量空前的專用模塊進一步降低了功耗。
欲獲取更多關于如何利用 Virtex-5 器件低功耗性能的資料,請訪問www.xilinx.com/cn//power。
Xilinx 功耗估算器(XPE)
2006年1月上世的Xilinx 功耗估算器(XPE),是一種基于電子數據表的功耗工具,支持VirtexTM-4 和最新推出的 Virtex-5 和 SpartanTM-3 FPGA 系列產品。XPE 被設計用來替代網絡功耗工具,是所有新型 XilinxFPGA 系列產品在初步設計時使用的主要功耗估計工具。與以往的功耗估計工具相比,XPE 的主要優(yōu)勢在于改進的用戶界面、更高的精度和對重要數據更好的顯示方法。
XPE 的概要頁顯示了能量使用的完整概述,首先是資源類型,接著是電源電壓。你能夠使用概要頁上的導航按鈕來查詢更詳細的信息。XPE 會自動顯示一些圖表,幫助用戶創(chuàng)建能量使用圖。
繼發(fā)布初始版本之后,Xilinx 又陸續(xù)發(fā)布了一些更新版本的XPE,包括了許多附加特性和精度的提高。www.xilinx.com/cn/power上提供了這些版本和它們所支持的 Virtex-5 和Spartan-3E 器件的列表。
Kevin Bixler
Xilinx公司功耗工具產品市場工程師
入門
NI LabVIEW FPGA模塊幫助DAQ系統的開發(fā)者靈活自如地進行應用程序編程以實現各類輸入/輸出操作。 用戶無需預先了解VHDL等硬件設計工具,便可將LabVIEW代碼嵌入FPGA芯片并獲得硬件定時的速度和可靠性。
讓我們先從數據采集硬件的常用組件切入論題。 假設您擁有了模數轉換器(ADC)、數模轉換器(DAC)和數字輸入/輸出線,則所有I/O便要根據實際操作接受某種方式的定時和控制。 典型的多功能數據采集設備采用功能齊全的ASIC,滿足了大多數的功能性需求。
比如:M系列DAQ設備通過DAQ-STC2,控制著各類硬件組件的定時和觸發(fā)。 智能DAQ硬件(如:R系列DAQ設備)區(qū)別于市面上的其他任何數據采集設備,因為在控制設備功能方面智能DAQ用基于FPGA的系統定時控制器取代了傳統ASIC,從而使得所有模擬和數字I/O都能根據特定應用操作接受相應的配置。 可重配置FPGA芯片通過NI LabVIEW FPGA模塊進行編程,此時NI LabVIEW的數據流模式仍舊適用,不過采用了一組新函數控制最底層的設備I/O。
LabVIEW FPGA I/O節(jié)點并不通過NI-DAQmx函數負責實現常見的任務和功能,而是靈活自如地在各個通道最底層上運行。 通過以下各部分的內容,我們將了解NI-DAQmx的特定實例,并學習如何通過智能DAQ定制各類數據采集任務。
定時和觸發(fā)
實現高級數據采集的智能DAQ主要用于定制定時和觸發(fā)。 下方的范例程序框圖展現了:NI-DAQmx幫助實現的觸發(fā)式模擬輸入任務。
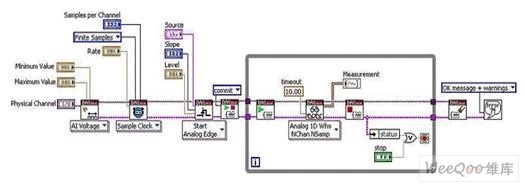
圖1. 通過NI-DAQmx實現的觸發(fā)式模擬輸入
如圖1所示,智能DAQ并未使用不同函數配置通道,而是通過名為I/O節(jié)點的函數讀寫各路模擬和數字通道。 讓我們看看使用NI LabVIEW FPGA中I/O節(jié)點所獲得的相同功能。
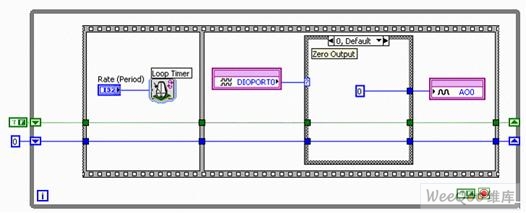
圖2. 通過智能DAQ和NI LabVIEW FPGA實現的觸發(fā)式模擬輸入
上圖既沒有針對全局通道、采樣時鐘、觸發(fā)的配置函數,也沒有開始、停止和清除等任務。 所有內容都被1個簡單的模擬I/O讀取所取代;全部定時都為本地LabVIEW結構(如:While循環(huán)和條件結構)所控制。由于整個程序框圖均在FPGA硬件內執(zhí)行,LabVIEW代碼的運行便體現出硬件定時的速度和可靠性。
讓我們更深入地了解一下該程序框圖的運行方式。 模擬I/O節(jié)點并不指定某個采樣速率,而使用For循環(huán)采集各個樣本。 與之對應的ADC在I/O節(jié)點被調用時,負責對輸入信號進行實際數字化,因而通過For循環(huán)接受定時。 若想在100 kHz的頻率下進行信號采樣,針對循環(huán)的延遲就必須設定為10 ?s。 循環(huán)的定時器函數從第2輪循環(huán)迭代開始便確保著特定的時間延遲,用戶因而能夠通過順序結構保證樣本之間存在著指定的時間間隔。 NI LabVIEW FPGA*能強大的條件結構,實際代表了用于封裝各類代碼的硬件觸發(fā)。 由于所有的函數和結構都通過邏輯單元在硬件內運行,所以條件結構確保開始具有實時10 ?s時間精度的采樣。 最后需指出的是,由于操作位于硬件層,只涉及幾個層次的抽象處理,因此用戶無需清除任務ID或釋放內存。
就基于FPGA的智能DAQ硬件而言,其真正的優(yōu)勢是能夠定制各類定時和觸發(fā),并在硬件中進行信號處理和決策。 現在讓我們了解一下:針對某類自定義應用,需對模擬輸入觸發(fā)做出哪些修改。 若我們希望在2路模擬輸入通道的某路電壓超過指定范圍時便觸發(fā)采集,又該如何修改呢? 借助NI LabVIEW FPGA,此類任務的執(zhí)行易如反掌。
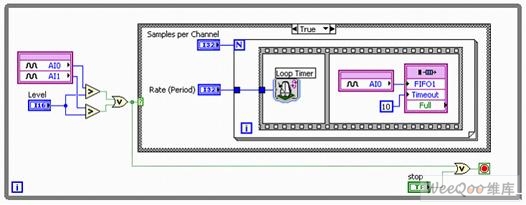
圖 3. 通過智能DAQ和NI LabVIEW FPGA實現的自定義觸發(fā)式模擬輸入
這里,我們已經為程序框圖添加了第2個I/O節(jié)點和第2個比較函數,以及1個布爾“或”函數。 智能DAQ硬件為所有的模擬輸入通道提供專用ADC,因而2路通道能夠接受同步采樣;同時,只要任何1路通道的電壓超過了指定范圍,條件結構便會執(zhí)行“真”條件,并開始以10 ?s時間精度進行采樣。 請記住:缺少智能DAQ便不可能生成類似的觸發(fā);在其他DAQ硬件上應用時,觸發(fā)需要具有更高延遲的軟件定時來實現。 如果此后我們希望通過擴展將監(jiān)控范圍從2路通道延伸至全部8路通道,甚至希望添加數字觸發(fā),就需要簡化自定義代碼。 添加預觸發(fā)掃描后,用戶便可對輸入通道不斷進行采樣并將數據傳送至FIFO緩沖器。 觸發(fā)器一旦接受讀取,FIFO緩沖器和此后的采樣便可經由DMA通道,被傳送至主機。
如果我們希望借助NI-DAQmx驅動,對第2模擬輸入通道進行采樣,則該程序框圖與圖1所示的內容相差無幾。然而限制依然存在,因為2路通道均被迫引用相同的觸發(fā)器并以相同的時鐘頻率進行采樣。 現在我們來看看:智能DAQ和NI LabVIEW FPGA幫助實現的各類多通道采樣。
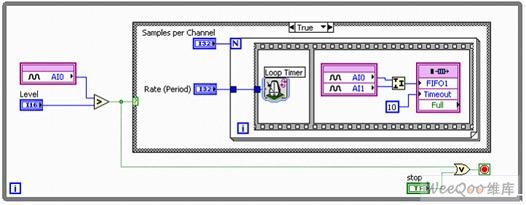
圖4. 通過智能DAQ實現的觸發(fā)式同步模擬輸入
圖4(上圖)展現了:如何基于模擬輸入通道0中的模擬觸發(fā)器,對2路不同的模擬輸入通道進行同步采樣。由于智能DAQ設備均配有獨立的ADC,在同一I/O節(jié)點中的2路通道可在完全相同的時刻接受采樣。 典型的多功能DAQ設備可通過一個ADC多路復用所有通道,因此,各路通道必須共享相同的采樣時鐘和觸發(fā)線。 圖5(下圖)展現了:智能DAQ硬件其實能夠以獨立的速率,對不同的模擬輸入通道進行采樣。 在獨立回路中放置模擬輸入I/O節(jié)點后,每路通道會以完全不同的速率進行采樣,然后各自通過2條DMA通道讀寫硬盤。
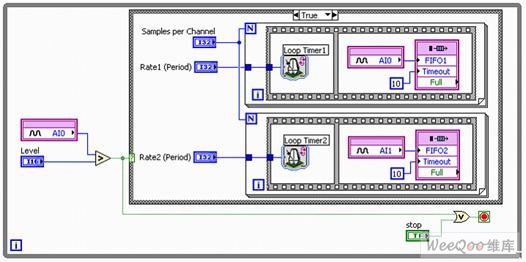
圖5. 通過智能DAQ實現的觸發(fā)式多速率模擬輸入
最后需指出的是,我們若是希望2路通道具有相互獨立的采樣率和開始觸發(fā),則可參照圖6,將所有I/O節(jié)點都部署在并行循環(huán)結構中。該方式充分利用了FPGA的并行性,確保了各項任務能夠使用專用資源并在執(zhí)行時完全獨立于其他采集任務。
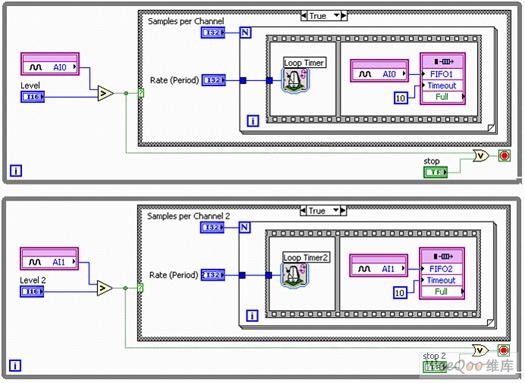
圖6. 通過智能DAQ實現的獨立觸發(fā)式多速率模擬輸入
同步
DAQmx驅動程序提供多種同步選擇,幫助建立輸入和輸出的時間相關性。 在下方的程序框圖中,模擬輸入通道和模擬輸出通道借助數字觸發(fā)實現同步;過程中,需對模擬輸入指定數字觸發(fā),并使用模擬輸入的觸發(fā)器信號觸發(fā)產生模擬輸出。
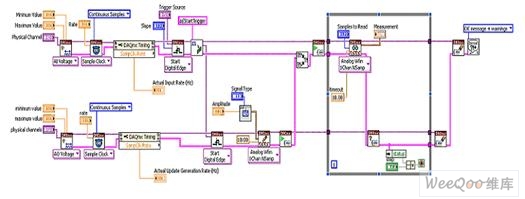
圖7. 通過NI-DAQmx實現的同步模擬輸入和輸出
用戶可通過智能DAQ硬件輕而易舉地執(zhí)行同步任務,而無需借助任務ID和板載信號路由。 本處即顯示了NI LabVIEW FPGA中的內容。
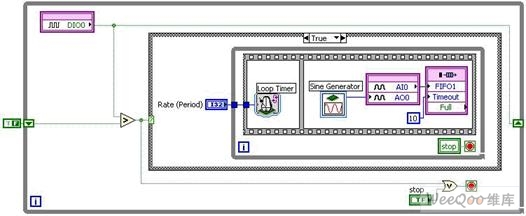
圖8. 通過智能DAQ實現的同步模擬輸入和輸出
此處,我們再次通過條件結構在FPGA芯片上執(zhí)行硬件觸發(fā),而數字通道0上的上升沿則啟用了真條件中的代碼。 在順序結構中,模擬輸入與輸出的節(jié)點在同時接受調用的過程中,幾乎沒有任何抖動;而我們只要簡單地在各個獨立的While循環(huán)內嵌入模擬I/O節(jié)點,即可令其擁有獨立的采樣速率。 另外值得注意的是: 程序框圖中顯示的正弦發(fā)生器函數是1個Express VI,可幫助用戶在查找表(LUT)中交互式地配置正弦值。
圖8中的智能DAQ程序框圖與圖7中的DAQmx VI皆具有相同的功能,而唯有智能DAQ才能為自定義任務提供相應的靈活性。 舉例為證:如需添加1個暫停觸發(fā),我們只消在內部While循環(huán)中添加1個條件結構,并通過另一個數字I/O節(jié)點選擇真條件或假條件,即可輕松完成任務。 對硬件進行編程的強大功能,實現了各類I/O的定時與同步。
多功能同步的另一例證體現為:通過板載計數器產生有限脈沖并將計數器輸出用作模擬輸入的采樣時鐘。 該過程是進行可重觸發(fā)式有限采樣的常用手段。 下圖顯示了開展此類采集所必需的DAQmx代碼。
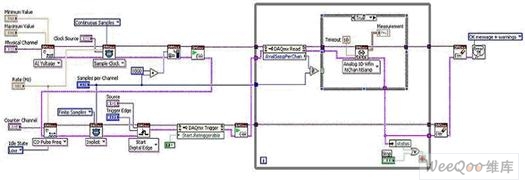
圖9. 通過NI-DAQmx實現的可重觸發(fā)式有限模擬輸入
現在,讓我們對下圖內容和呈現相同功能的NI LabVIEW FPGA程序框圖,加以比較。
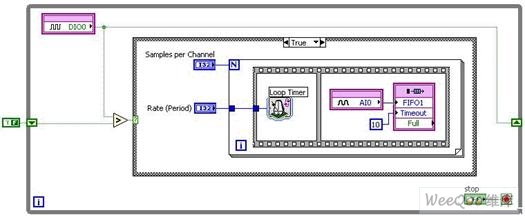
圖10. 通過智能DAQ和NI LabVIEW FPGA實現的可重觸發(fā)式有限模擬輸入
由于NI LabVIEW代碼在硬件層運行,圖10中的驅動配置步驟顯然得到了極大精減。 我們已經借助簡單的數字輸入線和For循環(huán)結構,創(chuàng)建了硬件可重觸發(fā)式有限采集。 圖9中的程序框圖使用2個板載計數器,創(chuàng)建出可重觸發(fā)的有限脈沖序列;典型的多功能DAQ設備只有2個計數器。 而借助NI LabVIEW FPGA,智能DAQ硬件卻能夠將任意一條數字線配置成計數器。 我們將在之后的段落里,涉及更多“通過智能DAQ運行計數器/定時器”的內容。
我們能夠借助由頻率觸發(fā)的采集,進一步地推進智能DAQ在硬件定時方面的靈活性特性。 用戶可通過高速板載決策計算輸入信號的頻率,而后選擇條件結構中所需的代碼;這一點是使用典型多功能DAQ設備所無法企及的。 在多設備的同步進程中,智能DAQ還可提供用于PCI板卡的RTSI總線或是用于PXI模塊的PXI觸發(fā)總線。 這些外部定時和同步線還可通過程序框圖上的I/O節(jié)點接受訪問。
模擬波形的生成
不少多功能DAQ設備都配有模擬輸出通道,能夠為了生成連續(xù)的模擬波形而需要用到FIFO緩沖。 生成的波形可將FIFO用作循環(huán)緩沖區(qū),且無需從主機處接受任何更新數據,即可連續(xù)不斷地重新生成一系列的模擬值。 通信總線的有無對此影響不大,因為并沒有針對設備的頻繁數據讀寫。 而如果波形需要修改,就必須重新啟動輸出任務并向FIFO寫入新數據。 另一個辦法是向硬件FIFO設備連續(xù)讀寫數據,而這又會導致輸出任務出現時滯。 借助智能DAQ,用戶能夠將波形輸出結果存儲于硬件,甚至能夠通過硬件觸發(fā)改變波形,進而創(chuàng)建任意波形發(fā)生器。
下方的函數發(fā)生器范例通過數字輸入線,觸發(fā)了輸出波形中的改動。 通過組合數字I/O線0與1,我們取得了應用于模擬輸出的4種不同狀態(tài)或稱條件。
圖11a. 配有智能DAQ條件0的函數發(fā)生器 – 零輸出
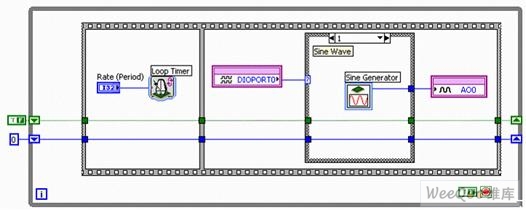
圖11b. 配有智能DAQ條件1的函數發(fā)生器 – 正弦波
當兩線皆呈現低電平時,執(zhí)行條件0;如圖11a所示,輸出值為0 V常量。而當DIO線0呈現高電平而DIO線1呈現低電平時,條件1將在模擬輸出0上執(zhí)行并生成一個正弦波。用戶可通過該正弦生成結構(圖11b)中的正弦發(fā)生器Express VI,配置NI LabVIEW FPGA必需的參數,交互地配置正弦波。
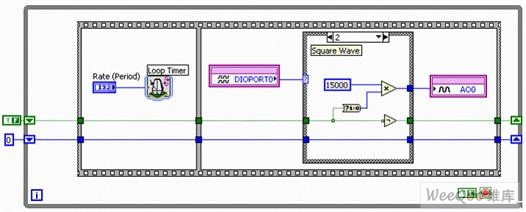
圖11c. 配有智能DAQ條件2的函數發(fā)生器 – 方波
條件2(圖11c)能夠在While循環(huán)的每輪迭代中,輕松切換布爾值。 數值較低時,整數15000便被寫入模擬輸出AO0,以對應16位DAC內由輸出寄存器存放的數值:15000。 16位有符號整數可以包含-32768到32767之間的數值。當輸出電壓范圍介于-10 V和10 V時,向模擬輸出AO0寫入-32768會生成-10 V電壓,而寫入32767則生成10 V電壓。該例中,因我們的寫入值為15000,則生成的電壓將低于5 V。(數學公式為: 15000/32767 * 10 V = 4.5778 V) 通常,條件2會輸出一個在0 V和4.578 V之間變換的方波。
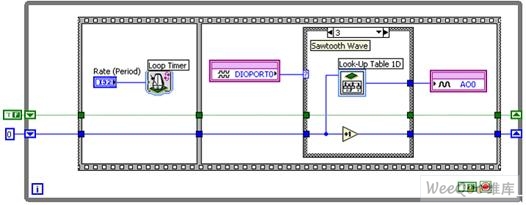
圖11d. 配有智能DAQ條件3的函數發(fā)生器 – 鋸齒波
當DIO 0和DIO 1均呈現高電平時,便執(zhí)行最后一個條件(圖11d);其間,須借助查找表(LUT)連續(xù)生成一個鋸齒波。 作為另一類Express VI的查表VI,既能存儲任意波形值,也能通過編程建立波形值的索引。 該例中,接受配置的鋸齒波可在模擬輸出通道0上生成。
通過將所有的值都存儲在FPGA上,用戶在降低總線依賴性的同時,也確保了波形更新時硬件定時的速度和可靠性。 之前各部分中所描述的模擬輸入的觸發(fā)和同步靈活性同樣適用于模擬輸出;借助智能DAQ,用戶能夠以不同速率,完全獨立地更新各路模擬輸出通道。 這意味著:用戶可在不影響其他通道輸出結果的前提下,修改單個周期性波形的頻率。 請注意:大多數數據采集硬件均不具備此項功能。
計數器/定時器的操作
如前所述,典型的多功能DAQ設備只有2個板載計數器,而智能DAQ則能在各條數字線上運行計數器功能。 數字I/O節(jié)點能夠在NI LabVIEW FPGA中利用名為單周期定時循環(huán)的專業(yè)結構,幫助用戶在2.5 MHz至200 MHz的特定頻率范圍內執(zhí)行代碼。 例如,借助40 MHz的時鐘,用戶可使用單周期定時循環(huán),在各條數字線上創(chuàng)建40 MHz計數器。 圖12(下圖)展現了程序框圖的樣式。
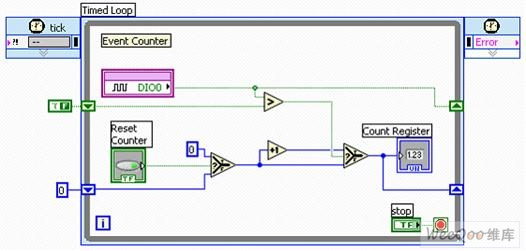
圖12. 配有智能DAQ的簡單事件計數器
由于計算值基于U32(32位整數)的數據類型被發(fā)送至顯示控件,該代碼便在FPGA芯片上生成了1個40 MHz的32位計數器。 用戶可對其進行數次復制與粘貼,令不同數字線上的多個計數器都能夠彼此完全并行地運行。 通過對智能DAQ中參數的設置可以實現定時器操作的自定義。 通過選擇,用戶能夠每隔2個上升沿便進行1次計數器遞增,甚至能基于計數寄存器的值觸發(fā)模擬采集。 許多復雜的計數器操作(如:有限脈沖序列生成和級聯式事件計數)均需要使用2個計數器,這意味著使用典型多功能設備中的所有板載計數器。 在總共160條數字線的幫助下,智能DAQ硬件上定時器的最大數量很少受到I/O可用性的影響,而往往取決于FPGA芯片的大小。 由于NI LabVIEW代碼運行于硅芯片中,因而用戶無需“裝備”或“重新裝備”通用計數器,即能全面控制計數器的運行。
圖13(下圖)中的范例使用計數器,生成了一個連續(xù)脈沖序列并將暫停觸發(fā)器置于NI-DAQmx中。
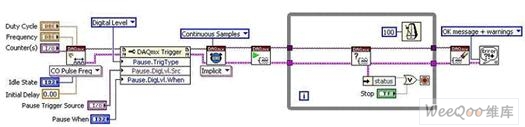
圖13. 連續(xù)脈沖序列的生成和配有NI-DAQmx的暫停觸發(fā)器
在NI LabVIEW FPGA中,暫停觸發(fā)器無需接受配置,因為只需簡單的條件結構便能在硅芯片中實現相同的功能。 此處是通過智能DAQ運行時所展現的相同功能(圖14)。
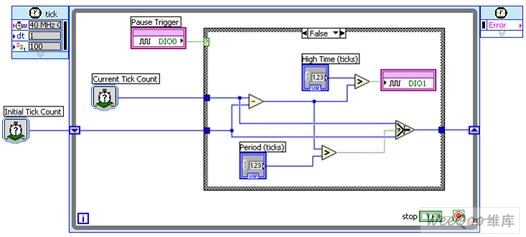
圖14. 連續(xù)脈沖序列的生成和配有智能DAQ的暫停觸發(fā)器
在這種情況下,數字I/O線DIO0用作暫停觸發(fā),而脈沖將在數字I/O線DIO1上生成并輸出。使用單周期定時循環(huán)可令各個脈沖獲得25 ns的分辨率,因為這將成為單個計時在使用40 MHz定時源時的值。
數字I/O應用
智能DAQ硬件提供多達160條硬件定時數字線,令諸多數字應用成為可能。 我們已經學習了如何使用數字I/O實現觸發(fā)、同步及計數器/定時器的運行,而智能DAQ還可用于誤碼率測試、數字模式匹配、脈沖寬度調制、正交編碼器和數字通信協議。 自定義或標準形式的串行接口均能直接通過數字定時框圖編程來實現。 舉例說明,SPI便是一款與硬件組件(如:微控制器或ADC)進行通信時最常用的串口協議。 圖15(下圖)展現了在進行16位SPI通信時,3條必要數字線所對應的定時框圖。

圖15. SPI通信輸入定時框圖
如定時框圖所示,所有16位數據均在每個時鐘周期上順次傳遞,而片選控制線(chip select line)則呈現低電平。 現在,我們來看看在NI LabVIEW FPGA中,如何通過智能DAQ硬件上的3條數字線進行此類編程。
在過去的半個世紀里,集成電路技術的進步不斷刷新著全球電子信息產業(yè)的形態(tài),五光十色的新產品、新應用也改變了人類的生活方式。然而,被新技術“寵壞”了的消費者越來越“喜新厭舊”,電子產品的市場壽命周期日益縮短,而企業(yè)對于產品差異化的不懈追求又進一步壓縮了單個產品的市場空間。與此同時,工藝技術的升級也讓產品的開發(fā)成本呈幾何級數上升。市場在呼喚一種能夠降低研發(fā)成本、縮短開發(fā)周期并具有設計靈活性的產品。在此背景下,FPGA(現場可編程門陣列)產業(yè)逐漸壯大并顯露出不可阻擋的氣勢。
搶食ASIC/ASSP市場
研發(fā)成本的上升抬高了ASIC(專用集成電路)和ASSP(專用標準電路)的研發(fā)門檻。調研機構IBS提供的數據顯示,在集成電路的90納米節(jié)點,其研發(fā)成本約為2000萬美元;到65納米節(jié)點研發(fā)成本已接近4000萬美元;目前最先進的32納米和28納米工藝技術的研發(fā)成本大約為9700萬美元;而到了22納米節(jié)點,其研發(fā)成本預計將突破1.5億美元。通常,集成電路設計企業(yè)針對某種產品的研發(fā)成本與該產品的銷售收入之比為1∶5。也就是說,當設計進入32納米/28納米之后,企業(yè)只有在對其產品的銷售預期大于5億美元的前提之下才會投入資源進行研發(fā)。采用尖端工藝技術的ASIC和ASSP勢必逐步退守到量大面廣的產品領域,而在一些市場空間較小的細分領域,我們將看到采用最新技術的FPGA和工藝水平相對較低的ASIC/ASSP進行較量。
“技術的進步是FPGA‘勢不可擋’的原動力。”賽靈思公司亞太區(qū)銷售與市場副總裁楊飛在接受《中國電子報》記者采訪時表示,“根據我們的統計,在90納米工藝節(jié)點,ASIC和ASSP只有不到25%的‘傳統領地’會受到FPGA的挑戰(zhàn);而在引入28納米工藝之后,ASIC和ASSP將有超過75%的應用領域面臨FPGA的競爭。不僅如此,FPGA還利用自身的優(yōu)勢,在無線通信、智能視頻監(jiān)控等多個領域解決了傳統ASIC、ASSP和DSP器件無法解決的問題。”
市場調研機構Gartner提供的數據似乎印證了楊飛的觀點:自1998年以來,全球ASIC新增項目數量逐年遞減,2009年的降幅甚至達到21.7%;ASSP情況稍好,其新增項目數量自2005年以來逐年遞減,預計到2013年,新增項目數將由2004年的4762項減少為3262項。當然,值得一提的是,ASSP的整體市場仍在快速增長。
“當然,在傳統的消費類電子行業(yè),ASIC產量大,具有絕對的低成本優(yōu)勢,占據了很大的市場份額。但是在工業(yè)領域等其他應用方面,基于可編程邏輯器件的解決方案將繼續(xù)扮演重要角色。”Altera公司亞太區(qū)高級市場經理羅嘉鸞表示,“多年來,ASIC的成本在不斷攀升,我們已經領先于ASIC行業(yè)。特別是在40納米節(jié)點,我們贏得的大部分設計實際上來自Altera非主要用戶。也就是說,他們曾一直使用競爭對手的FPGA解決方案,或者是ASIC、ASSP和DSP。”
“展望未來,可編程邏輯市場前景一片光明。”賽靈思公司總裁兼CEO Moshe Gavrielov表示,“據分析家預測,2010年,該行業(yè)的市場增長率將在45%以上,達到48億美元。而根據Raymond James Financial公司提供的數據,可編程邏輯市場將攫取原先屬于ASIC陣營的150億美元到200億美元的市場份額。” 
尋找新“甜蜜點”
雖然FPGA行業(yè)的整體發(fā)展速度高于ASIC/ASSP,但對于FPGA的從業(yè)者來說,如何更深入地了解設計人員的需求,通過產品創(chuàng)新為FPGA尋找新的市場“甜蜜點”,是他們一直都面臨的挑戰(zhàn)。
“2010年,FPGA產業(yè)最令人矚目的發(fā)展機遇是滿足越來越高的帶寬需求,在以前僅采用ASIC和ASSP的應用中使用FPGA。”Altera公司高級市場副總裁Danny Biran分析說。美國的相關機構預測,到2015年,美國IP流量每年將達到澤字節(jié)(1021字節(jié)),云計算、視頻游戲、VoIP和視頻點播等應用推動了帶寬需求的增長。為此,系統開發(fā)人員需要擁有高速收發(fā)器的硬件,在這方面,最新的FPGA要比其他硬件解決方案更具優(yōu)勢。
因為ASIC、ASSP流片時,僅收發(fā)器的IP費用就高達幾十萬美元,更不要說先進工藝節(jié)點在流片時費用的快速攀升和諸多風險了。
而且,不僅僅是通信市場對高速收發(fā)器有需求,2010年逐步聯網的工業(yè)自動化市場也提出了類似需求。工業(yè)以太網令系統更容易維護、管理和更新。這也是一類以前并沒有使用FPGA的應用。由于工業(yè)領域的以太網標準種類繁多,只有采用FPGA,用戶才能針對最佳應用使用合適的協議,顯然,FPGA為這類應用帶來最佳性價比。
同時,中國在2010年加速推進三網融合,FPGA行業(yè)人士也與三網融合各環(huán)節(jié)設備企業(yè)共同分析需求,在通信解決方案、高密度EdgeQAM解決方案、視頻和高端音頻平臺方案等領域尋找新的機遇。在一些環(huán)節(jié),是采用FPGA還是ASIC和ASSP,設備企業(yè)尚無定論,FPGA企業(yè)正在優(yōu)化FPGA方案的性價比,可以預見,三網融合市場上的爭奪戰(zhàn)已經打響。同其他新市場一樣,在三網融合市場,FPGA產業(yè)同樣面臨如何培訓工程師的挑戰(zhàn)。“這種融合趨勢下,許多數字工程師必須重新學習射頻領域的高頻設計技術。”愛特公司高級產品市場推廣經理Rajiv Nema說。
此外,在高端視頻監(jiān)控市場,1080p高清和智能跟蹤以及分析對數據處理提出更高需求,在一些方案中,DSP平臺已無法支撐,為此,一些高端監(jiān)控平臺正轉向FPGA的并行處理技術。
消費ic37在過去并不是FPGA的優(yōu)勢領域,但是,最近一兩年也發(fā)生了驚人的轉變。“對消費類電子產品而言,搶先把產品推向市場就意味著可以確立市場優(yōu)勢,并獲得更高的利潤。”賽靈思公司亞太區(qū)銷售與市場副總裁楊飛介紹說,“FPGA與生俱來的靈活性恰恰迎合了縮短上市周期的需求。因此,我們看到越來越多的平板電視、手機等消費類電子產品正在大量使用FPGA。”當然,這與FPGA在功耗、成本和尺寸上的創(chuàng)新和改善有緊密聯系,這些改善在結合FPGA天然的優(yōu)勢,為消費電子設計人員提供了性價比更高的方案。北京立功致遠科技有限公司Actel FPGA市場推廣與技術支持工程師郭立龍就舉例介紹說,FPGA器件的尺寸已經小到3mm×3mm,可以貼在手機的主板與屏幕之間的排線上面,經過FPGA接口轉換的TFT時序擺脫了原配手機屏幕的限制,現在手機可以使用一個任何接口標準的屏幕了。三星的一款帶有前后雙屏幕的數碼相機在設計中大膽引入FPGA,將背后大屏影像縮放至前面小屏上。相信三星等領頭羊企業(yè)將引領更多消費電子系統設計企業(yè)采用FPGA。
吸引軟件工程師
除了尋找市場上的“甜蜜點”外,FPGA行業(yè)也正在試圖通過改變自身的產品特性和設計流程來吸引更多的系統設計工程師。他們的途徑之一就是引入ARM。引入ARM為FPGA行業(yè)帶來兩大明顯的轉變:一是使FPGA平臺成為較為開放、有更多應用案例、為更多工程師所熟悉的SoC開發(fā)平臺;二是FPGA的設計流程從以硬件設計為主轉變?yōu)橐攒浖䴙橹鳌_@兩大轉變無疑將吸引更多的系統設計工程師特別是軟件工程師應用FPGA。
愛特公司全球首席執(zhí)行官John East分析說,從理想角度來看,系統設計工程師真正想要的是一個可定制化的解決方案。大多數系統設計人員都是提前確定處理器內核,而對其他各部分的要求直到設計周期的最后一分鐘都可能改變。因此,大部分設計人員都期待有這么一個解決方案,它包含嵌入式業(yè)界標準內核,帶有直觀易用的設計流程,能夠執(zhí)行所選外設的經全面驗證的IP組合以及一個由業(yè)界領先工具組成的生態(tài)系統,最好還有與外界連接的片上可編程模擬功能。而愛特針對這樣的需求設計推出了集成ARM Cortex M3的SmartFusion單芯片。“我認為,很快地,SoC就將成為設計的起點,而不是終點。”John East說。
賽靈思公司亞太區(qū)市場及應用總監(jiān)張宇清則表示,賽靈思將ARM Cortex-A9引入FPGA,打造了一個“以處理器為主、以FPGA為輔”的系統。而以處理器為核心的設計方法可以支持一個以軟件為核心的開發(fā)流程。
“從全球范圍看,軟件工程師與硬件工程師數量之比超過了10∶1,而且系統設計的工作量中80%以上是軟件開發(fā)。為此,10年來,FPGA廠商一直在尋求把眾多的嵌入式軟件工程師引入到主要由硬件設計工程師構成的用戶群體中。”ARM公司嵌入式應用市場經理羅霖對《中國電子報》記者說。他進一步分析說,以前,以FPGA作為開發(fā)平臺,設計流程一般是要先開發(fā)硬件,然后再開發(fā)軟件。但將ARM引入FPGA后,系統設計可以先從軟件開發(fā)的角度來定義產品功能和模塊,哪些部分需要軟件就開發(fā)軟件,哪些部分需要使用FPGA,就再做硬件開發(fā)。“這種以處理器為核心的系統定義和設計方法可以支持一個以軟件為核心的開發(fā)流程。”羅霖說,“這樣,軟件工程師會越來越多地被引入到項目中來。”吸引了軟件工程師用戶群體,無疑將拓展FPGA的市場領地。
| 以下內容含腳本,或可能導致頁面不正常的代碼 |
|---|
| 說明:上面顯示的是代碼內容。您可以先檢查過代碼沒問題,或修改之后再運行. |
不少工業(yè)分析家相信,2005年它將取代60%的PCI接口市場。英特爾也預計今年的PC、筆記本電腦、服務器、工作站、通信和嵌入式產品將廣泛采用PCI Express,并正在全力推動跨平臺、從上到下的向PCI Express的快速遷移。
這一技術發(fā)展趨勢也對FPGA供應商的發(fā)展戰(zhàn)略產生了相當大的影響。例如,Altera高級市場副總裁Jordan Plofsky最近接受本刊記者采訪時表示:“今年我們將為Stratix GX、Stratix II GX、CyClone II和HardCopy II提供PCI Express接口支持。”這意味著Altera今年可望向用戶市場提供PCI Express內核。
 |
|
Plofsky: Altera今年 |
事實上,Altera早就在為此積極做著準備。就在今年二月份,Altera和PMC-Sierra公司合作發(fā)布了一整套基于Altera可編程邏輯和PMC-Sierra收發(fā)器技術的高速串行I/O解決方案。這一合作使得Altera低成本CyClone II FPGA、Stratix II FPGA和HardCopy II結構化ASIC的用戶能夠通過PMC-Sierra PM8358 QuadPHY 10GX串行/解串器(即SERDES收發(fā)器)將他們使用的器件無縫移植到高速串行協議系統中。這一組合解決方案使得用戶能夠應用時下流行的高速串行通信協議(如PCI Express、Serial RapidIO、10G以太網、光纖通道、通用協議無線接口等)來實現芯片間、PCB板之間以及系統間的通信連接。對習慣于FPGA/收發(fā)器方案的用戶,Altera也提供了集成SERDES的解決方案。
PMC-Sierra公司市場總監(jiān)Travis Karr也強調:“QuadPHY 10GX SERDES和Altera FPGA的結合能夠為用戶提供最具成本效益的解決方案,它支持速率在1.2至3.2Gbps之間的主要新興串行協議。”
大多數臺式PC和服務器供應商預計在近期將采用PCI和PCI Express兩種插槽并存的方式,然后在一兩年里逐步淘汰PCI插槽。PCI Express在筆記本電腦中的應用也在快速上升之中。
市場研究公司Insight6??分析師Nathan Brookwood表示,PCI Express總線的另一個好處是能夠為用戶提供更大的靈活性。PCI總線需要用戶打開機箱插入各種硬件卡,而PCI Express總線允許PC整機供應商直接把連接邏輯制作到主板上,用戶只需要簡單地在機箱后面插入線纜就可以了。
另一主要FPGA供應商Xilinx目前已可向用戶提供PCI Express內核,其Virtex II Pro FPGA集成了RocketIO 3.125Gbps收發(fā)器,完全可以支持單向通信速率為2.5Gbps的單通道PCI Express接口的實現。
隨著FPGA成本的直線下降(目前最便宜的FPGA價格已掉到3美元左右),FPGA和HardCopy II結構化ASIC越來越多地成為開發(fā)中小規(guī)模ASIC和ASSP的用戶的第一選擇。Plofsky透露,目前不少IC品牌供應商開始直接采用我們的Stratix II FPGA和HardCopy II產品開發(fā)其ASSP。
Gartner在一份市場研究報告中也指出,大約65-70%的數字ASIC設計可以用HardCopy和HardCopy II來完成,這意味著HardCopy的市場可以在2006年達到150億美元。
目前Altera密度最高的Stratix II FPGA可以開發(fā)最高220萬門的ASIC,百萬門ASIC的成本已只有15美元。HardCopy II結構化ASIC支持的最高工作頻率為350MHz。
“驗證是目前中國工程師在開發(fā)百萬門以上FPGA時遇到的最大技術挑戰(zhàn),”Plofsky指出,“信號完整性和EMI/EMC問題也是主要的設計挑戰(zhàn),尤其當他們開發(fā)復雜和高速的FPGA設計時。”
2004年Altera最成功的產品是Cyclone,其全球付運量約達到了750萬片,最大的應用領域是各種類型的TV,如LCD和PDP TV。在亞太市場,它主要應用在日本、韓國和臺灣地區(qū)的消費電子產品中(如便攜式多媒體播放機中)。
Altera大中國區(qū)總經理趙典鋒也透露,Stratix已經在日本和韓國的電信基礎設施產品中(如基站)進入了批量發(fā)貨階段,Stratix II目前也已中標了不少設計,預計在不久的將來Hardcopy II也可望進行批量交貨階段。
]]>新興接口標準綜述
如果查看一下典型通信系統的結構,可以看出很多元件都需要相互進行通信。為滿足數據通道中各種元件的不同需求,因而出現了各種不同的接口標準。要了解各種接口的優(yōu)缺點,就需要查看元件本身及每個元件所發(fā)生的通信類型。這里將從光電接口開始,然后逐一介紹內部元件,直至交換架構(switch fabric).
a.與串并行轉換器相連的光電器件
在高速光纖通信系統中,傳輸的數據流需要進行格式轉換,即在光纖傳輸時的串行格式及在電子處理時的并行格式之間轉換。串化器-解串器 (一般被稱作串并行轉換器) 就是用來實現這種轉換的。串并行轉換器與光電傳感器間的接口通常為高速串行數據流,利用一種編碼方案實現不同信令,這樣可從數據恢復嵌入的時鐘。視乎所支持的通信標準,該串行流可在1.25Gb/s (千兆以太網)、2.488Gb/s (OC-48 / STM-16)、9.953Gb/s (OC-192 / STM-64) 或10.3Gb/s (10千兆以太網)條件下傳輸。
b.串并行轉換器至成幀器接口
在Sonet / SDH的世界中,光纖中的數據傳輸往往采用幀的形式。每幀包括附加信息(用于同步、誤差監(jiān)視、保護切換等)和有效載荷數據。傳輸設備必須在輸出數據中加入幀的附加信息,接收設備則必須從幀中提取有效載荷數據,并用幀的附加信息進行系統管理。這些操作都會在成幀器中完成。
由于成幀器需要實現某些復雜的數字邏輯,因而決定了串并行轉換器與成幀器間所用的接口技術,采用標準CMOS工藝制造的高集成度IC.目前的CMOS工藝不能支持10Gb/s串行數據流(盡管很多人認為未來的CMOS工藝可以實現此項功能),因此串并行轉換器與成幀器間需要并行接口。目前最流行的選擇是由光網絡互聯論壇 (Optical Internetworking Forum) 開發(fā)的SFI-4,該接口使用兩個速度達622Mb/s的16位并行數據流(每個方向一個).SFI-4與目前很多新興接口一樣,使用源同步時鐘,即時鐘信號與數據信號共同由傳輸器件傳輸。源同步時鐘可顯著降低時鐘信號與數據信號間的偏移,但它不能完全消除不匹配PCB線路長度引起的偏移效應。16個數據信號和時鐘信號均使用IEEE-1593.6標準LVDS信令。該接口僅需在串并行轉換器與成幀器間來回傳輸數據,距離較短,因此無需具備復雜的流控制或誤差檢測功能。
以太網中也存在類似接口。在10千兆以太網PHY的物理編碼子層(PCS)與物理介質連接(PMA)層之間,IEEE-802.3ae規(guī)范提供了一種被稱作XSBI的接口。這種“10千兆16位接口”在每個方向都具有16位并行數據流及源同步時鐘。數據和時鐘均使用IEEE-1593.6標準LVDS信令。數據通道使用64b/66b編碼方案,其時鐘頻率為644MHz.
該10千兆以太網規(guī)范使用串行接口連接MAC(介質訪問控制)層和PHY(物理)層。這個被稱作XAUI的接口,也被稱為“10千兆連接單元接口”,這是一種使用四通道的串行接口,每個通道傳輸2.5Gb/s有效載荷數據,8b/10b編碼使每個通道的比特率高達3.125Gb/s.該接口一般用于連接MAC和包含PHY及光器件的獨立模塊。根據幾家制造商的多源協議開發(fā)的Xenpak光模塊使用XAUI接口。后文還將提到XAUI也用于系統背板。
c.成幀器與網絡處理器及其它元件間的接口
成幀器與網絡處理間傳輸的數據可代表很多不同的數據流。Sonet/SDH幀中包含的附加數據表明數據有效載荷中每個數據流的位置,該信息需要在成幀器與網絡處理器及相關器件間傳輸,如分類引擎和流量管理器。此外,網絡處理器和相關器件還實現各種復雜的任務,如數據包傳向交換芯片的時序安排,管理數據包內容以確保沒有非法數據進入網絡,以及測量帶寬以便特定應用或用戶享有優(yōu)先權。由于這些任務很復雜,因此需要在成幀器與網絡處理器間實施流控制方案。
成幀器、網絡處理器與相關器件間通常使用的接口包括Utopia接口、POS-PHY接口、SPI接口和Flexbus接口。每個接口的后綴為 “l(fā)evel X”,其級別表明標稱數據速率。Level 2即指每個方向的數據速率為622Mb/s,Level 3為2.488Gb/s,level 4為9.953Gb/s,Level 5為39.8Gb/s.因此POS-PHY Level 4的標稱帶寬為9.953Gb/s.Utopia接口是為包含固定長度ATM單元的數據流而設計的。Utopia的規(guī)范由ATM論壇頒布。
POS-PHY接口 (Sonet物理層上的包) 由PMC-Sierra和Saturn開發(fā),很多特性與Utopia接口相同,有一項改進功能值得注意,即POS-PHY能滿足不同長度數據包的需要,而Utopia只適用于固定單元長度。這表明POS-PHY接口是為無需ATM層,即可在Sonet/SDH傳輸層上直接傳輸長度變化的IP包的應用而設計的,因此被稱作“Sonet上的數據包”.
Flexbus接口由AMCC開發(fā),可處理Sonet傳輸層上的變長度IP包。AMCC的Flexbus Level 4已獲光網絡互聯論壇采納,作為SPI Level 4 Phase 1(一般縮寫為“SPI-4.1”),并已經作為業(yè)界標準規(guī)范發(fā)布。該規(guī)范在每個方向上提供64位并行點至點數據通道,它使用HSTL class 1 I/O,源同步時鐘頻率為200MHz,還提供四分之一速率接口和16位并行數據通道。
POS-PHY Level 4也已經被光網絡互聯論壇采納,命名為SPI Level 4 Phase 2 (通常縮寫為“SPI-4.2”).該接口具有采用IEEE-1593.6標準LVDS的16位并行數據通道,源同步雙數據速率時鐘頻率最小為311MHz.SPI-4.2的許多應用則使用頻率更高的時鐘,因為該接口除了傳輸數據有效載荷外,還傳送包標簽和路由信息。因此,設計者常常采用SPI-4.2,每個信號對的數據速率高達840Mb/s,每個方向的累計帶寬可達13.4Gb/s.
盡管SPI-4.2是為Sonet上數據包而開發(fā),它已被通信業(yè)的其它應用所采納。作為能支持多數據流而且每個數據流中都具有流控制的靈活接口,它可用作10G以太網的有效接口,還可用于存儲區(qū)域網絡(SAN).目前市場上有各種采用SPI-4.2接口的新產品,還有一些產品正在開發(fā)之中,除了Sonet / SDH成幀器和網絡處理器,還包括TCP 卸載引擎(TOE)和10G以太網MAC.
d.網絡處理器與交換架構間的接口
網絡處理器與相關器件及交換架構間的接口有兩種
類型:一類為不需要在背板傳輸數據的接口,另一類為需要在背板傳輸數據的接口。對于第一種接口,位于同一塊電路板的網絡處理器芯片組和交換架構間的接口可用CSIXLevel1接口實現。該接口采用CSIXLev…
類型:一類為不需要在背板傳輸數據的接口,另一類為需要在背板傳輸數據的接口。
對于第一種接口,位于同一塊電路板的網絡處理器芯片組和交換架構間的接口可用CSIX Level 1接口實現。該接口采用CSIX Level 1包格式,包括為交換架構提供路由指令的報頭,以及用于誤差檢測及糾正的報尾,還包括數據載荷本身。控制CSIX規(guī)范的網絡處理器論壇將進一步完善該規(guī)范,增加從一個NPU芯片組通過交換芯片傳至另個NPU芯片的額外指令。這將成為CSIX Level 2規(guī)范的最主要推進力。該規(guī)范還定義了每個方向中使用至多128個HSTL一類I/O的電氣互連,其源同步時鐘頻率高達250MHz.CSIX Level 1協議與CSIX Level 1電氣規(guī)范無關,無論NPU芯片組和交換架構間的經由背板的通信采用何種電氣標準,仍可使用CSIX Level 1協議。
對于第二種接口,即NPU芯片組與交換架構間需要在通過背板通信,仍然可以使用CSIX Level 1協議,但這種電氣接口并不合適。信號將穿過連接器,從端口卡到達系統背板,經過數英寸到達另一個連接器,然后進入交換卡。有諸多原因使得越來越多的設計者選擇具有嵌入式時鐘的串行接口來實現這些連接。首先,串行接口可最大限度地減少電路板與背板連接器的引腳數,從而可減小插拔力及對操作系統中電路板的可能損害。其二,在信號中嵌入時鐘和數據的串行接口可完全避免時鐘偏移問題。時鐘偏移是PCB中數英寸長的并口所面臨的主要問題。其三,串行信號的背板設計者還可提高傳輸速率,因為不存在時鐘偏移,也就沒有對未來性能的限制。
被成功用作串行背板標準的接口是XAUI,它是為10千兆以太網開發(fā)的。該規(guī)范適用于通道排列電路,無論四通道軌線長度是否匹配,符合XAUI的器件均能接收無誤差數據。該接口使用差分電流模式邏輯信令,它還采用交流耦合模式,允許電路板間的參考電壓不同。
e.控制板接口
目前本文所提到的接口都用于“數據通道”,即數據從光纖傳輸介質到達交換架構,然后返回光纖通道。但由于通信系統具有復雜的“控制板”,負責統計數據收集、流量監(jiān)視、系統管理及維護等功能,因此需要強大的處理能力運行軟件以實現這些功能。這些構建控制板處理器的接口正如設想的那樣,與數據通道的接口明顯不同。數據通道接口主要用于在兩個器件間傳輸數據(即點對點鏈接),控制板接口則是與具有不同元件的一個或多個微處理器相連接: 背板收發(fā)器、DSP、數據板器件的控制端口等。實現這些靈活的互連需要完全不同類型的接口。
這類系統過去都是圍繞多點復接的中心總線構建的。實現PCI總線架構的32位/ 33MHz及最近采用的64位/ 66MHz標準已經用于通信系統中。最近64位/ 133MHz PCI-X更用于高端服務器。但是,由于數據板處理的帶寬已經增加,控制板的帶寬也要提高。很多設計者發(fā)現共享總線帶寬不足以滿足多個器件的需求。因此,出現一類新型接口。
這類新接口采用點至點連接,用源同步時鐘減少時鐘偏移。差分信令可提高數據傳輸率,減少交換噪聲和功耗。但真正的創(chuàng)新在于使用交換架構或通道器件,實現控制應用中所需的多點互連。
已獲得Motorola及RapidIO貿易聯合會支持的RapidIO是使用交換架構實現點至點鏈接的接口。該接口的傳輸層規(guī)定數據如何封裝在包中,每個包都具有數據源和目標信息,交換架構將數據包送往合適的目的地。RapidIO在每個方向上提供8個或16個位,采用250MHz至1.0GHz雙數據速率。此外,串行RapidIO可使用具有8b/10b編碼的1通道或4通道數據,嵌入時鐘達3.125Gb/s,它還具有CML差分信令。Motorola已經推出幾種使用并行RapidIO的通信處理器。
AMD及HyperTransport聯盟開發(fā)的HyperTransport使用通道器件實現點至點鏈接。數據以包的形式傳輸,每個包均包括數據源和目標信息。接收數據的通道器件按照數據包報頭確定是將數據傳至鏈中的下一個器件,還是直接處理數據。目前的HyperTransport規(guī)范需要寬度為2至16位的并行數據。未來規(guī)范可支持更高速率。PMC-Sierra和Broadcom已經為HyperTransport通信產品推出基于MIPS的處理器。
PCI-SIG已經推出高速率PCI-X.它們使用與最初PCI-X相同的64位總線帶寬,可支持雙數據速率和四倍數據速率。PCI-X 533是速率最快的版本,最大總計帶寬達34.1Gb/s.
解決接口沖突
設計工程師如何面對這些紛繁蕪雜的接口標準。實際上,對于給定的設計情況,設計者選擇接口的余地并不大。他們一般根據系統所需的成本及功能,選擇合適的標準產品。設計者必須選擇最合適的器件。但這可能導致接口標準沖突,因為最好的標準器件由于接口標準不兼容,會引起互用性問題。在這種情況下,設計者可如此選擇:重新選擇與接口兼容的標準器件,但可能會造成不能滿足功能需要或系統的成本要求,或者使用橋接器件避開不兼容的接口。現在已經推出很多具有高性能接口IP及高速物理I/O的FPGA,可滿足10Gb/s以上數據通道的通信系統的要求。
Actel正在開發(fā)各種可編程邏輯器件,結合高級接口技術和最新推出的Axcelerator系列高速FPGA架構。首款產品將具有速率高達3.125Gb/s的集成串并行轉換器通道和硬連線物理編碼子層,它們能自動處理XAUI和串行RapidIO所需的8b/10b編碼和通道排列。這些器件還具有實現LVDS信令的高速通用I/O,可交互使用SPI-4.2、HyperTransport和并行RapidIO等接口標準。這些器件還將集成各種知識產權內核,以便應用于要求苛刻的橋接產品。]]>

Stratix III FPGA芯片圖。

StratixIV FPGA芯片圖。
在本文第一部分的討論中,我們知道了在目前的基于FPGA的圖像處理設計流程,以C++等高級語言編寫的算法函數模型必須采用手動方式編碼為RTL。但手動建立RTL的方法不但耗時,而且容易出錯,對后端布線延時問題非常敏感。因此我們必須考慮采用能夠從ANSI C++建模算法迅速轉換到運行在FPGA硬件中的RTL實現方法。在接下來的第二部分討論中,我們就將討論如何利用Catapult的ASIC功能和Altera加速庫自動順利實現這一設計過程。
為順利實現這一非常耗時的過程,Catapult C高級綜合設計過程首先對算法進行描述,然后選擇目標技術。算法描述是純粹的ANSI C++源代碼,只對功能進行說明。并行和接口協議等硬件要求可通過約束在Catapult中實現,從而也指導了綜合過程。
例如,下面的算法是一個基本有限沖擊響應(FIR)濾波器,使用免費的Mentor Graphics Algorithmic C數據類型(加鏈接)來定義接口和內部位寬度。
C++算法并沒有說明需要多少乘法器以及什么類型的乘法器來實現硬件。因此,系統規(guī)劃人員不用在實施細節(jié)上花費太多精力就能夠有效的建立算法。
下一步是確定目標技術和關鍵規(guī)范。在Catapult中,目標技術可以是ASIC或者FPGA,與源代碼描述無關。Catapult C綜合使用專用技術庫特征參數來建立最佳運算庫,例如加法器和乘法器等。這一特性描述過程收集器件專用資源詳細的面積和時序信息,使Catapult能夠建立技術預知計劃,不會浪費HLS探察過程中RTL綜合時間。其結果是快速的前端面積/性能估算,得到專用技術RTL輸出。
指定好目標技術以及時鐘頻率后,設計人員可以使用自動高級綜合技術自由地進行設計。由于自動過程比手動RTL編碼快得多,設計人員能夠關注更多的選項,綜合考慮面積和性能,所實現的硬件完全滿足設計目標要求。高級綜合工具對目標技術非常清楚,根據時鐘頻率要求來選擇合適的運算,在需要的地方增加系統級流水線,確保不會違反時鐘頻率約束。設計人員可以使用開環(huán)和環(huán)流水線等高級綜合約束,研究從最短串聯到全并聯實現的多種微體系結構(對比圖1和圖2中的具體實現)。

圖1:串聯FIR實現。

圖2:并聯FIR實現。
在接下來的第三部分討論中,我們將討論如何選擇調度所需要的運算以滿足時鐘頻率約束,以及如何采用高級綜合資源約束來減小后端走線延時,敬請留意。
]]>| 以下內容含腳本,或可能導致頁面不正常的代碼 |
|---|
| 說明:上面顯示的是代碼內容。您可以先檢查過代碼沒問題,或修改之后再運行. |
消費電子能否支撐FPGA產業(yè)
消費電子市場受到金融風暴的影響尤為劇烈,因此不同的FPGA廠商對消費電子市場的前景有許多爭論。Altera首席執(zhí)行官(CEO)及董事會主席John Daane認為,房地產泡沫帶來的繁榮帶給消費額外的收入去購買更多的消費電子產品。約有40%的電子產品屬于消費性,再加上超過30%與電腦相關的產品,所以實際上接近75%市場的都在消費領域,目前很容易看到該行業(yè)受到的沖擊;同時美國作為一個消費大國的時代也徹底遠去。而如果把半導體產業(yè)劃分成不同的細分市場,就可以看到無線通訊、軍用等比其他領域的處境要好,因此FPGA廠商應該將重點放在這些更擅長的市場。
行官(CEO)及董事會主席John Daane")
圖1,Altera首席執(zhí)行官(CEO)及董事會主席John Daane
FPGA廠商SiliconBlue首席執(zhí)行官Kapil Shankar卻認為,消費市場的衰退并不會是一個長期的現象,而最終會驅動更多低功耗FPGA產品的產生。他舉例說,上網本目前使用普通筆記本的處理器,因而缺乏足夠的移動能力;另一方面,嵌入式移動處理器又反而缺乏足夠的功能,如圖形和視頻顯示、投影等。在這些領域使用FPGA則是合理的選擇,可為產品增加集成度和移動性的同時保證豐富的功能;而用傳統ASIC不能在小批量定制化產品中實現較低的成本。
行官Kapil Shankar")
圖2,SiliconBlue首席執(zhí)行官(CEO)Kapil Shankar
Actel則通過其低功耗Flash FPGA產品進入消費領域。Actel副總裁Richard Kapusta說,低功耗不代表“低卡路里”,因為對功耗的測量并沒有一個準確或完善的方法。與基于SRAM的技術不同,基于Flash的FPGA產品從結構上帶來的真正功耗優(yōu)勢,只有傳統SRAM的千分之一。同時,Flash架構具有小尺寸、單芯片的優(yōu)勢,還可以做到更安全和更穩(wěn)定。另外,混和信號FPGA是市場的新成員。它的特殊性在于其并不完全針對低成本或低功耗應用,而是要幫助系統實現

圖3,Actel副總裁Richard Kapusta
制程工藝是否代表了半導體的一切
John Daane指出,ASIC恪守于陳舊的制程技術來試圖維持性價比,而可編程器件卻能保持前進的步伐,至少要領先3~4代。半導體的成本隨晶圓尺寸呈幾何級數增加,可編程邏輯方案則能真正實現最小的晶圓尺寸;而如果想與例如DDR3等目前的主流存儲技術和新功能實現接口,130nm的ASIC將不能滿足你的性能需求。
ASIC廠商則對制程工藝的提升持保留態(tài)度。創(chuàng)意電子(Global Unichip)市場部總監(jiān)黃克勤博士說,FPGA雖然利用先進的制程技術有效推動了芯片的各項指標,但單純制程的演進不足以滿足應用對功能不斷增加的需求;另外,功耗幾乎已經成為所有應用的重中之重,但這些正是FPGA的弱項。從市場角度看,FPGA只應用于小批量市場,而市場的最終裁判是整體出貨量。不得不承認ASIC有許多弊端,但引入Fabless代工廠模式后,不再需要為某個設備或應用單獨投資一家晶圓廠,也就避免了上億美元風險極高的投資,其他的問題也可以迎刃而解。
意電子(Global Unichip)市場部總監(jiān)黃克勤博士")
圖4,創(chuàng)意電子(Global Unichip)市場部總監(jiān)黃克勤博士

圖5,Xilinx全球市場高級副總裁Vincent Ratford
對于制程工藝之爭,在FPGA廠商之間也存在不同的看法。Xilinx全球市場高級副總裁Vincent Ratford指出,客戶的需求不僅僅是芯片本身,而是整個解決方案,以及如何用這些方案實現更復雜的應用。盲目地沖向制程技術上的新節(jié)點,而僅僅創(chuàng)造一個單獨的芯片、技術,或設備遠遠不夠,沒有足夠的IP、軟件等支持也并不是市場所需要的。因此,廠商必須能夠針對某個特定領域推出適合的產品,并考慮到在這些應用場景下的功耗。最重要的一點是,客戶需要一個與今天ASIC設計相兼容的設計方法,這也是Xilinx提出的“目標設計平臺”概念的一個重要元素。
Dave Greenfield")
圖6,Altera HardCopy產品線的高級總監(jiān)Dave Greenfield
Altera HardCopy產品線的高級總監(jiān)Dave Greenfield表示,應用FPGA來主導產品的前期開發(fā)最重要的是,可以把你的產品更早地提供給你的軟件開發(fā)團隊和早期客戶。從客戶獲得及時的反饋十分必要;軟件部門如果能較早地得到產品,則可對代碼進行更多的優(yōu)化。所以前期用FPGA開發(fā)再通過ASIC實現大批量生產的模式能讓系統成本有效降低.
]]>圖16. 16位SPI通信程序框圖
圖16中,外部While循環(huán)確保了所有代碼均能連續(xù)執(zhí)行,而寫入布爾輸入控件則通過條件結構啟動著數據傳遞。 順序結構中的第一框架將片選控制線(chip select line)設置為低電平,之后由中間框架寫入數據位并將時鐘線切換16次。 最終,第三順序框將片選控制線(chip select line)設置回TRUE狀態(tài),并將數據線重置為默認的FALSE狀態(tài)。 這一簡單范例只是借助智能DAQ進行數字通信時的一項內容。 用戶若想應用數字握手,便需為ACK(備用)和REQ(暫停)線準備2路通道,其中一路通道面向并行運作的時鐘信號和數據線。
數字線會時常抖動,在使用機電接觸時更是如此,然而用戶可通過NI LabVIEW FPGA,選擇不同方式,在數字輸入線上添加去抖動濾波器。 在消除狀態(tài)的錯誤改動時,數字去抖動濾波器確保數值的變化能夠保持一段最短的時間,因而規(guī)避了因抖動引發(fā)的錯誤讀取。 圖17展現了如何通過智能DAQ實現此項功能的內容。
圖17. 智能DAQ硬件上的數字濾波器程序框圖
數據傳輸方式
配備NI-DAQmx驅動程序的傳統多功能DAQ和智能DAQ之間的最大差異在于:數據傳輸的執(zhí)行方式。 NI-DAQmx驅動程序將承擔由設備至主機的各項傳輸任務,此項操作中NI LabVIWE FPGA會對基于FPGA的所有板載硬件進行編程。 用戶可通過多種途徑緩沖設備上的板載數據,并使用不同方式(如:DMA通道或中斷請求)傳輸數據。
NI LabVIEW FPGA中的FIFO緩沖區(qū)在LabVIEW項目瀏覽器中接受配置,并能借助板載內存或硬件邏輯獲得運行。 圖18顯示了如何經由項目瀏覽器,在板載塊存儲器中配置整數的FIFO緩沖區(qū)。
圖18. NI LabVIEW FPGA中的FIFO配置
FIFO一經創(chuàng)建,便能用于NI LabVIEW FPGA程序框圖上多個循環(huán)之間的數據傳遞。 圖19中的范例顯示:數據先被寫入左側循環(huán)中的FIFO,并隨即從右側循環(huán)中的FIFO被讀出。
圖19. 通過FIFO和多循環(huán)實現的NI LabVIEW FPGA程序框圖
同樣通過LabVIEW FPGA FIFO獲得應用的直接存儲器訪問(DMA)通道,在項目瀏覽器中接受了類似的配置。
圖20. NI LabVIEW FPGA中的DMA FIFO配置
圖21. 通過DMA FIFO和位組裝實現的NI LabVIEW FPGA程序框圖
所有的DMA FIFO數據傳輸寬度均為32位;因此,當其傳遞源自16位模擬輸入通道的數據時,往往能夠合并2路通道或2個樣本上的數據再進行傳輸,從而提高帶寬使用率。 這即是圖21所展現的位組裝。當數據被直接傳遞到主控計算機的內存后,便可通過在Windows環(huán)境下運行的NI LabVIEW主接口函數接受讀取(圖22)。
圖22. 通過DMA FIFO讀取和位拆裝實現的主接口代碼
如圖22所示,主接口程序框圖引用FPGA終端VI,然后使用While循環(huán)連續(xù)讀取DMA FIFO。 32位的數據被分解為2路16位通道,在波形圖表上接受采樣和繪制。 主接口VI還能對FPGA VI前面板上的各類顯示控件和輸入控件進行讀寫操作;在這種情況下,“停止按鈕”輸入控件也被寫入。
結論
盡管DAQ-STC2等固定ASIC能夠滿足數據采集的大多數需求,然而,唯有借助智能DAQ中基于可重新配置FPGA的I/O定時和控制,方能實現高度靈活性和完全定制。 借助NI LabVIEW FPGA,觸發(fā)和同步任務獲得了簡化,因為通過繪制圖形化程序框圖即可充分滿足用戶需求;借助獨立的模擬和數字I/O線,智能DAQ可利用FPGA提供的實際并行。 R系列智能DAQ設備已經針對多速率采樣、自定義計數器操作和頻率高達40 MHz的板載決策,為多功能數據采集進行了各項可能的修繕。
]]>- 高性能
- 高邏輯容量
- 低功耗
- 更多高級特性
FPGA 的基本客戶訴求是更短的上市時間、更豐富的功能、支持各種不斷發(fā)展的標準、更低的風險、現場可升級性以及更低的系統成本等。我們的 FPGA 產品可滿足您不斷改進性能、容量、功耗和成本的要求。
Virtex-5 系列結合了65 納米工藝技術的固有優(yōu)勢和創(chuàng)新設計,該創(chuàng)新設計立足于我們對產品應用的更深入的理解。本文中,我將對Virtex-5 器件進行概述,解釋其基礎技術,同時簡短回顧世界領先的FPGA 架構設計背后的故事。
工藝技術和架構創(chuàng)新
Virtex-5 FPGA 基于65 納米的三柵極氧化層技術, 使用先進的硅組合模塊(ASMBLTM) 架構并且實現了更高級別的系統集成。這個全新的產品系列提供了一個高級平臺,可以滿足用戶對于建造具有更高性能、更高密度、更低功耗和更低成本的可編程系統日益增長的需求。滿足上述一個或者兩個需求也許比較容易,但是挑戰(zhàn)在于我們要同時滿足所有這些需求。我們通過將先進的IC 工藝、創(chuàng)新的架構以及電路設計相結合,成功地應對了這些挑戰(zhàn)。首先在 Virtex-4 系列中引入的成熟的 ASMBL 芯片版圖架構,可以提供所要求器件資源(邏輯、存儲器、算術、I/O和IP)的最優(yōu)組合,從而為以下四個新平臺創(chuàng)造了最佳條件:
- 針對高性能邏輯進行優(yōu)化的 LX 平臺
- 針對具有低功耗串行 I/O 的高性能邏輯進行優(yōu)化的 LXT 平臺
- 針對具有低功耗串行 I/O 的高性能算術和存儲密集型 DSP 進行優(yōu)化的SXT 平臺
- 針對嵌入式處理和超高速串行 I/O 進行優(yōu)化的 FXT 平臺
相對于Virtex-4 系列,Virtex-5 系列中配置最高的型號的平均速度提高了30%,容量提高了65%,動態(tài)功耗降低了35%,芯片面積縮小了45%,結果實現了達到每項功能的最低成本。
高性能和高密度
ExpressFabricTM 技術實現了邏輯和局部互連布線。它將查找表 (LUT)、六個獨立的輸入和一個新的對角互連結構結合在一起,如圖1 所示。相對于 Virtex-4 架構而言,ExpressFabric 技術利用更少的 LUT層次以及更少的串行連接(面向相鄰構件)實現了組合邏輯。這種方法縮短了數據通路延遲,從而提高了設計性能。

圖1 - Virtex-5 ExpressFabric 技術
先進的6-LUT 邏輯結構
多年以來,四輸入 LUT 一直是業(yè)界標準。但是,在65 納米工藝條件下,相較于其它電路(特別是互連電路),LUT 的常規(guī)結構大大縮小。一個具有四倍比特位的六輸入LUT (6-LUT) 僅僅將 CLB 面積提高了15% - 但是平均而言,每個 LUT 上可集成的邏輯數量卻增加了40%。更高的邏輯密度通常可以降低級聯 LUT 的數目,并且改進關鍵路徑延遲性能,如圖2 所示。

圖2 - 在性能和面積之間達到最佳平衡
我們選擇了一套客戶設計方案,然后使用 ISETM 8.1i 軟件實現該方案。對于每個設計,我們比較了Virtex-4 和 Virtex-5器件實現中所用的 LUT 數目,并將此信息和兆赫茲的性能提升相關聯。圖3 中的散點圖顯示了X軸上的性能提升百分比和Y軸上根據 LUT 數目的降低計算得出的面積縮小比例。這種新的6-LUTExpressFabric 技術在性能提升和資源節(jié)約方面都表現出色。
不同于競爭 FPGA 的是,Virtex-5FPGA 提供了真正的 6-LUT,你可以將它用作邏輯或者分布式存儲器,這時 LUT是一個64 位的分布式 RAM (甚至雙端口或者四端口)或者一個32 位可編程移位寄存器。每個 LUT 具有兩個輸出,從而實現了五個變量的兩個邏輯函數,存儲32 x 2 RAM 比特,或者作為16 x 2-bit 的移位寄存器進行工作。

圖3 - Virtex-5 FPGA 和 Virtex-4 FPGA 設計套件的評測基準
新的對角對稱互連
一種新的對角對稱互連模式通過在更少的布線跳接中獲得更多的空間來提高性能。關于Virtex-5 和Virtex-4 FPGA 互連模式(每個正方形代表一個 CLB)的比較,請參見圖1。通過色標可以看出,使用Virtex-5 FPGA 使該模式更加對稱,同時利用更少的跳接到達了更多的 CLB。憑借布局布線軟件工具,這種對稱性可以取得更好的結果。
這些特性對于 Virtex-5 FPGA 的用戶來說是完全透明的,并且能夠被 ISE 軟件自動執(zhí)行,從而帶來更加簡單的可布線性和更好的總體性能。
最低功耗的先進 FPGA 解決方案
Virtex-5 器件系列采用領先的65 納米、三柵極氧化層、11 層銅布線的 CMOS 工藝技術。“三柵極氧化層”是指采用不同的晶體管柵極氧化層厚度的數目。I/O 晶體管必須可以承受 3.3V 的電壓,因此使用相對較厚的氧化層,但是邏輯和其它核心功能所使用的超高速晶體管則一般采用超薄氧化層。不幸的是,超薄氧化層和超低閾值電壓不可避免地帶來較高的泄漏電流。然而,FPGA 中有很多晶體管不需要很高的速度(特別是那些配置存儲單元)。從Virtex-4系列開始,Xilinx 率先采用了第三種中間柵極氧化層厚度,專門針對這一類晶體管。這種三柵極氧化層方法允許我們對器件電路的性能和功耗進行微調。它使得Virtex-5器件可以提供業(yè)界領先的性能,同時能夠大幅度降低泄漏電流,從而降低了靜態(tài)功耗。
此外,新的 6-LUT 邏輯結構在每個LUT 中融合了更多的邏輯塊,使用了較少的局部互連節(jié)點和更少的高電容節(jié)點(邏輯功能之間),降低了邏輯層次,從而縮短了路徑延遲。這種新的對稱布線還使相鄰邏輯之間的連接更加直接,這進一步降低了布線電容。VCCINT,核心供電電壓,現在是1.0V。所有這些因素都有助于總體動態(tài)功耗的降低。Virtex-4 系列的成功告訴我們,很多工程師將性能和功耗看作是系統設計中的兩個同等重要的約束條件;因此,我們既需要高性能,也需要低功耗。我們對 Virtex-5 的邏輯結構進行了徹底的改進,以便充分利用65 納米三柵極氧化層的CMOS 工藝,結果是誕生了迄今為止性能最高的結構,系統時鐘頻率超過550 MHz。和90 納米 Virtex-4 相比,Virtex-5 的靜態(tài)功耗大體相當,但動態(tài)功耗至少降低了35%。就像它的前輩一樣,Virtex-5 系列又一次提供了其他高級FPGA 系列難以比擬的低功耗解決方案。
適用于系統集成的高級特性
在Virtex-5 系列中,我們在每個時鐘管理管道 (CMT) 中加入了一個鎖相環(huán)(PLL),現在每個時鐘管理管道含有兩個數字時鐘管理器 (DCM) 和一個PLL。因此 CMT同時提供了兩個域(數字域和模擬域)的最優(yōu)特性:數字時鐘管理器所具備的強健的多功能性和精確的遞增相移能力,與模擬PLL 帶來的降低抖動性能。該系列中配置最高的型號具備六個可以產生和操作550MHz 時鐘的CMT , 從而支持Virtex-5 的邏輯和模塊功能。
同步雙端口 block RAM 是一個重要的功能塊。每個 block RAM 的大小已經增加到36 Kb,但是你可以將它用作兩個單獨的 18-Kb block RAM。數據總線寬度從1 位到36 位是可編程的。在簡單雙端口模式(一個端口寫,另一個端口讀),數據總線寬度可以高達72 位,有效地加倍了數據帶寬。你還可以關閉未被使用的18-Kb block RAM 以節(jié)省功耗。
該block RAM 帶有集成的 FIFO 控制邏輯,從而簡化了在高達 550 MHz 時鐘頻率下運行的異步(或同步) FIFO 的設計,同時無需消耗任何邏輯資源。
72 位寬的 block RAM 現在還包括64-bit 的檢錯誤和糾錯 (ECC) 控制邏輯。類似于集成的 FIFO 支持功能,該集成化 ECC 提高了存儲器的性能,同時消除了那些和傳統的基于結構的解決方案相關的成本。你還可以使用專用 ECC 邏輯來增強外部存儲器接口。
我們最新推出的 ChipSyncTM 技術大幅度增強和簡化了與外部設備尤其是外部存儲器(比如DDR、DDR2、 QDR II 和RLDRAM II)的連接。基于我們 LX50T 器件的存儲器開發(fā)系統 (ML561),包含通過硬件驗證的實用參考設計,該參考設計可以用于目前所有的主流存儲技術。
在 DSP 領域,我們推出了一個 25 x18-bit 的乘法器,主要用于更高效率的浮點設計。這些 DSP48E 邏輯片可以進行直接級聯,從而能夠在數字濾波或視頻廣播應用中實現更高的性能。直接級聯還可以節(jié)省功耗 - 和其它競爭方案比較,我們可以降低40%的功耗。Virtex-5 SelectIO? 技術繼續(xù)在業(yè)界保持領先地位。所有引腳實際上都支持目前使用的所有 I/O 標準,并且提供高達1.25 Gbps 的 LVDS 和 800 Mbps 的單端 I/O 性能。除了提供可編程輸入延遲(步長75ps ) 的 IDELAY 選項外, 新推出的ODELAY 選項為 FPGA 的輸出端提供了同樣精細的粒度。每個功能都可以在所有器件的引腳上進行單獨編程。IODELAY 功能是一個重要的特性,可以增強對高速源同步數據和時鐘的可靠發(fā)送和接收。目標應用包括板級偏斜補償、總線的位對準以及數據和時鐘信號的對準。該功能能夠讓 LVDS I/O 實現每對引腳高達1.25 Gbps 的速率。Virtex-5 LXT 、SXT 和 FXT 器件同樣提供了嵌入式串行收發(fā)器 - 在配置最高的 LXT 器件中包含的這種收發(fā)器的數目竟然高達 24 個。在開發(fā)高速串行收發(fā)器的第四代 RocketIO? 技術時,我們在降低功耗方面投入大量的精力。在3.2Gbps的峰值速率下,LXT RocketIO 收發(fā)器的功耗低于100 mW,使其成為所有FPGA 產品中功耗最低的收發(fā)器(參閱圖4)。

圖4 - RocketIO GTP 收發(fā)器
每個 Virtex-5 LXT RocketIO 收發(fā)器都是可編程的,可以實現各種速率,支持各種串行標準。我們面向每個標準(比如以太網、HD/SDI、串行RapidIO、FibreChannel 和 Aurora)推出了鏈路層IP。最后,我們預計到 PCI Express (PCIe)端點應用的普遍性,在硬件邏輯中集成了完整的 PCIe 端點協議。Virtex-5 LXT PCIe 端點模塊完全兼容 PCIe 標準規(guī)范的1.1 版本,可以支持x1、x2、x4 和 x8的通道實現方案。集成式硬 IP 節(jié)省了邏輯資源,并且提高了日益普及的 PCIe 應用的性能。對于 x4 PCIe 通道的實現而言,較之軟 IP 實現方案,Virtex-5 PCIe子系統模塊節(jié)省的 LUT 數目高達 8,500個。Virtex-5 器件提供了更多和更小的I/O bank。外部 I/O bank (配置最高的型號中含有八個 bank )也經過精心安排,從而方便 PCB 布線,在某些情況下可以節(jié)省 PCB 板的布線層級。
為了保證取得 FPGA 業(yè)界最佳的同步切換輸出 (SSO) 性能, 并且實現FPGA 業(yè)界最好的信號完整性 (SI) 解決方案,所有 Virtex-5 器件均利用 Xilinx的稀疏鋸齒技術進行插腳引線的對齊。這種方法確保每個 I/O 引腳都可以被電源引腳和地引腳緊密包圍,從而使電流環(huán)電感最小,進而提高了信號完整性。
結論
希望我前面的介紹能夠讓您更好地了解Virtex-5 器件及其背后的設計動因。我們非常希望系統設計界能夠接納這種全新的架構。我們希望看到您的下一代系統能夠從 Virtex-5 增強的性能和功能中獲益,將您的復雜設計提升到一個新的高度。
]]>將標準單元核可編程器件集成在一起并不意味著使ASIC更加便宜,或是FPGA更加省電。但是,它讓設計人員將雙方的優(yōu)點結合在一起。通過去掉FPGA的一些功能,設計人員可減少成本和開發(fā)時間,并增加靈活性。有時我們已經很難判定什么是嵌入可編程邏輯的ASIC,什么是嵌入標準單元的FPGA。“朗訊已經宣布他們能夠提供任何比例的FPGA或ASIC芯片。”In-Stat公司的分析師Max Baron說,“假如FPGA/ASIC的比例是60/40,這并不損害FPGA市場。”
ASIC嵌入可編程邏輯單元
Actel采取兵分兩路的戰(zhàn)略。這家反熔絲FPGA供應商服務于傳統的FPGA應用,產品有MX、SX及新型eX系列器件。Actel最近宣布了與ASIC制造商結盟的計劃,為SoC設計提供嵌入式FPGA IP。“我們努力使未來的ASSP和ASIC供應商有機會更早地進入市場,利用嵌入式內核獲得更長的市場生命期。”嵌入式FPGA集團總監(jiān)Yankin Tanurhan說。
VHDL語言是一種用于電路設計的高級語言。它在80年代的后期出現。最初是由美國國防部開發(fā)出來供美軍用來提高設計的可靠性和縮減開發(fā)周期的一種使用范圍較小的設計語言。但是,由于它在一定程度上滿足了當時的設計需求,于是他在1987年成為ANSI/IEEE的標準(IEEE STD 1076-1987)。1993年更進一步修訂,變得更加完備,成為ANSI/IEEE的ANSI/IEEE STD 1076-1993標準。目前,大多數的CAD廠商出品的EDA軟件都兼容了這種標準。
2.對CPLD/FPGA的結構比較熟悉。
有了這兩個條件才能在設計的過程中選用適當的器件從而提高設計的可靠性、提高器件的利用率及縮短設計的周期。但是有一個重大的問題是在于,如果你的產品有所改動,需要采用另外的CPLD/FPGA時,你將需要重新輸入原理圖。(改用不同的器件在今天這種競爭環(huán)境下是會經常發(fā)生的。頭兒們?yōu)榱颂岣弋a品的性能或者是降低產品的造價,提高保密性等等,都會考慮選用不同的器件。對他們而言只是做出一個決定,對我們而言卻是要我們付出更多的心血)。
2.使用編譯工具編譯源文件。HDL的編譯器有很多,ACTIVE公司,MODELSIM公司,SYNPLICITY公司,SYNOPSYS公司,VERIBEST公司等都有自己的編譯器。
3.(可選步驟)功能仿真。對于某些人而言,仿真這一步似乎是可有可無的。但是對于一個可靠的設計而言,任何設計最好都進行仿真,以保證設計的可靠性。另外,對于作為一個獨立的設計項目而言,仿真文件的提供足可以證明你設計的完整性。
4.綜合。綜合的目的是在于將設計的源文件由語言轉換為實際的電路。(但是此時還沒有在芯片中形成真正的電路。這一步就好像是把人的腦海中的電路畫成原理圖。--這是我的個人觀點,似乎在好多文獻中都沒有提到“綜合”的準確定義。至少,我讀過的幾本書中就沒有。)這一部的最終目的是生成門電路級的網表(Netlist)。
5.布局、布線。這一步的目的是生成用于燒寫(編程Programming)的編程文件。在這一步,將用到第4步生成的網表并根據CPLD/FPG廠商的器件容量,結構等進行布局、布線。這就好像在設計PCB時的布局布線一樣。先將各個設計中的門根據網表的內容和器件的結構放在器件的特定部位。然后,在根據網表中提供的各門的連接,把各個門的輸入輸出連接起來。最后,生成一個供編程的文件。這一步同時還會加一些時序信息(Timing)(?)到你的設計項目中去,以便與你做后仿真。